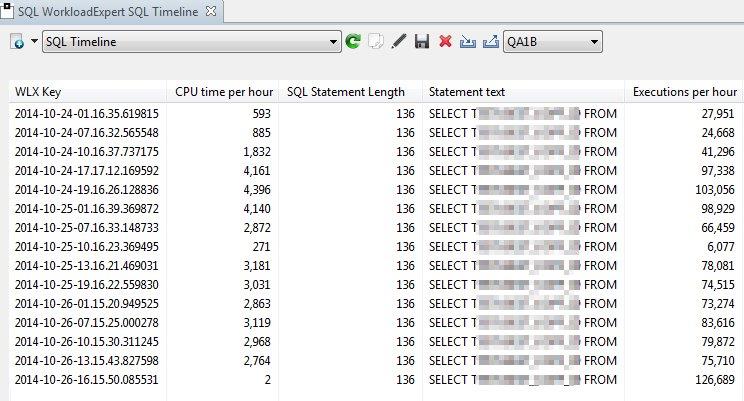
Well I must admit that I did not know what a long and painful birth this “little” newsletter would be!
First I had to get a whole bunch of installation jobs run, then a few APARs from good old IBM, and then I had to run the “enable” Spatial support job (DSN5ENB) and finally the Spatial bind job (DSN5BND). This took a while and gave me a few extra grey hairs…however if you follow the documented approach it all works – now of course it assumes that everyone in the world lives in the USA or the UK as continental Europe uses the comma as a decimal separator but the Spatial support has hard coded decimal point – This also cost me LOTS of grey hairs as I had to manipulate the data using the ISPF Editor to get the format “right”.
So there I am with 20 rows of IBM test data and a newsletter to write…hmmm…need more data methinks.. So I decide to use GOOGLE to find some data and Voila! I find 43,191 ZIPCODEs from the USA with Latitude and Longitude…of course it is comma separated…load into excel change the format and save away to then be uploaded to the host and then INSERTED into a new spatial table…All goes horribly wrong because you cannot use a column during the insert of a function to get a point… GRRR!!
But let us do what I did step by step:
First I created a little table to hold the data from the excel:
CREATE DATABASE ZIPCODE;
COMMIT;
CREATE TABLE BOXWELL.ZIPCODES
(
ZIP INTEGER NOT NULL,
CITY VARCHAR(64) NOT NULL,
STATE CHAR(2) NOT NULL,
LATITUDE DECIMAL(9 , 6) NOT NULL,
LONGITUDE DECIMAL(9 , 6) NOT NULL,
TIME_ZONE SMALLINT NOT NULL,
DST_FLAG SMALLINT NOT NULL
)
IN DATABASE ZIPCODE;
COMMIT;
Then I loaded it up with data
OUTPUT START FOR UTILITY, UTILID = LOAD
PROCESSING SYSIN AS EBCDIC
LOAD DATA FORMAT DELIMITED COLDEL ';' CHARDEL '"' DECPT '.'
INTO TABLE BOXWELL.ZIPCODES
(ZIP INTEGER,
CITY CHAR,
STATE CHAR,
LATITUDE DECIMAL,
LONGITUDE DECIMAL,
TIME_ZONE SMALLINT,
DST_FLAG SMALLINT)
RECORD (1) WILL BE DISCARDED DUE TO 'ZIP'
CONVERSION ERROR FOR BOXWELL.ZIPCODES
ERROR CODE '02 - INPUT NUMERIC INVALID'
(RE)LOAD PHASE STATISTICS - NUMBER OF RECORDS=43191 FOR TABLE
BOXWELL.ZIPCODES
(RE)LOAD PHASE STATISTICS - TOTAL NUMBER OF RECORDS LOADED=43191 FOR
TABLESPACE ZIPCODE.ZIPCODES
(RE)LOAD PHASE STATISTICS - NUMBER OF INPUT RECORDS NOT LOADED=1
(RE)LOAD PHASE STATISTICS - NUMBER OF INPUT RECORDS PROCESSED=43192
(RE)LOAD PHASE COMPLETE, ELAPSED TIME=00:00:01
DISCARD PHASE STATISTICS - 1 INPUT DATA SET RECORDS DISCARDED
DISCARD PHASE COMPLETE, ELAPSED TIME=00:00:00
UTILITY EXECUTION COMPLETE, HIGHEST RETURN CODE=4
The first record in the excel table was the headings record so it was OK to lose it by the way.
Then I created a new table with the LOCATION column and tried to INSERT like this:
CREATE DATABASE ZIPCODES;
---------+---------+---------+---------+---------+---------+---------+
DSNE616I STATEMENT EXECUTION WAS SUCCESSFUL, SQLCODE IS 0
---------+---------+---------+---------+---------+---------+---------+
COMMIT;
---------+---------+---------+---------+---------+---------+---------+
DSNE616I STATEMENT EXECUTION WAS SUCCESSFUL, SQLCODE IS 0
---------+---------+---------+---------+---------+---------+---------+
CREATE TABLE USA.ZIPCODES
(
LOCATION DB2GSE.ST_POINT ,
LONGITUDE DECIMAL(9 , 6) NOT NULL,
LATITUDE DECIMAL(9 , 6) NOT NULL,
STATE CHAR(2) NOT NULL,
TIME_ZONE SMALLINT NOT NULL,
DST_FLAG SMALLINT NOT NULL,
ZIP INTEGER NOT NULL,
CITY VARCHAR(64) NOT NULL
)
IN DATABASE ZIPCODES;
---------+---------+---------+---------+---------+---------+---------+
DSNE616I STATEMENT EXECUTION WAS SUCCESSFUL, SQLCODE IS 0
---------+---------+---------+---------+---------+---------+---------+
COMMIT;
---------+---------+---------+---------+---------+---------+---------+
DSNE616I STATEMENT EXECUTION WAS SUCCESSFUL, SQLCODE IS 0
---------+---------+---------+---------+---------+---------+---------+
INSERT INTO USA.ZIPCODES
SELECT DB2GSE.ST_POINT('POINT (LONGITUDE LATITUDE)' , 1003)
,LONGITUDE
,LATITUDE
,STATE
,TIME_ZONE
,DST_FLAG
,ZIP
,CITY
FROM BOXWELL.ZIPCODES
;
---------+---------+---------+---------+---------+---------+---------+
DSNT408I SQLCODE = -443, ERROR: ROUTINE GSEGEOMFROMTEXT (SPECIFIC NAME
STCO00002GFT) HAS RETURNED AN ERROR SQLSTATE WITH DIAGNOSTIC TEXT
GSE3049N Invalid WKT format, expecting a number instead of
LONGITUDE LATITUDE).
DSNT418I SQLSTATE = 38SV8 SQLSTATE RETURN CODE
DSNT415I SQLERRP = DSNXRUFS SQL PROCEDURE DETECTING ERROR
DSNT416I SQLERRD = -101 0 0 -1 0 0 SQL DIAGNOSTIC INFORMATION
DSNT416I SQLERRD = X'FFFFFF9B' X'00000000' X'00000000' X'FFFFFFFF'
X'00000000' X'00000000' SQL DIAGNOSTIC INFORMATION
---------+---------+---------+---------+---------+---------+---------+
DSNE618I ROLLBACK PERFORMED, SQLCODE IS 0
DSNE616I STATEMENT EXECUTION WAS SUCCESSFUL, SQLCODE IS 0
Oh dear… So now I wrote a select to generate a set of INSERTS like this:
SELECT 'INSERT INTO USA.ZIPCODES VALUES (' ||
'DB2GSE.ST_POINT(''POINT (' || LONGITUDE ||
' ' || LATITUDE || ')'' , 1003)' ||
', ' || LONGITUDE ||
' , ' || LATITUDE ||
' ,''' || STATE ||
''', ' || TIME_ZONE ||
' , ' || DST_FLAG ||
' , ' || ZIP ||
' ,''' || CITY || ''') §'
FROM BOXWELL.ZIPCODES ;To create the geometry for the LOCATION column you can use the ST_POINT function and that takes as input a LONGITUDE and a LATITUDE and, all important, the SRS_ID which tells the system which Spatial Reference System you are using – I use 1003 in my examples because my data is “old” and used the WGS84 standard. The supplied Geometries have these names and, more importantly, the SRS_IDs that must be used!
SELECT * FROM DB2GSE.ST_SPATIAL_REFERENCE_SYSTEMS;
---------+---------+---------+-------------+-
SRS_NAME SRS_ID
---------+---------+---------+-------------+-
DEFAULT_SRS 0
NAD83_SRS_1 1
NAD27_SRS_1002 1002
WGS84_SRS_1003 1003
DE_HDN_SRS_1004 1004
This SQL created output like this:
INSERT INTO USA.ZIPCODES VALUES (DB2GSE.ST_POINT('POINT (-71,013202 43,005895)' , 1003), -71,013202 , 43,005895 ,'NH', -5 , 1 , 210 ,'Portsmouth') §
INSERT INTO USA.ZIPCODES VALUES (DB2GSE.ST_POINT('POINT (-71,013202 43,005895)' , 1003), -71,013202 , 43,005895 ,'NH', -5 , 1 , 211 ,'Portsmouth') §
INSERT INTO USA.ZIPCODES VALUES (DB2GSE.ST_POINT('POINT (-71,013202 43,005895)' , 1003), -71,013202 , 43,005895 ,'NH', -5 , 1 , 212 ,'Portsmouth') §
INSERT INTO USA.ZIPCODES VALUES (DB2GSE.ST_POINT('POINT (-71,013202 43,005895)' , 1003), -71,013202 , 43,005895 ,'NH', -5 , 1 , 213 ,'Portsmouth') §
INSERT INTO USA.ZIPCODES VALUES (DB2GSE.ST_POINT('POINT (-71,013202 43,005895)' , 1003), -71,013202 , 43,005895 ,'NH', -5 , 1 , 214 ,'Portsmouth') §
INSERT INTO USA.ZIPCODES VALUES (DB2GSE.ST_POINT('POINT (-71,013202 43,005895)' , 1003), -71,013202 , 43,005895 ,'NH', -5 , 1 , 215 ,'Portsmouth') §
INSERT INTO USA.ZIPCODES VALUES (DB2GSE.ST_POINT('POINT (-72,637078 40,922326)' , 1003), -72,637078 , 40,922326 ,'NY', -5 , 1 , 501 ,'Holtsville') §
INSERT INTO USA.ZIPCODES VALUES (DB2GSE.ST_POINT('POINT (-72,637078 40,922326)' , 1003), -72,637078 , 40,922326 ,'NY', -5 , 1 , 544 ,'Holtsville') §
INSERT INTO USA.ZIPCODES VALUES (DB2GSE.ST_POINT('POINT (-66,749470 18,180103)' , 1003), -66,749470 , 18,180103 ,'PR', -4 , 0 , 601 ,'Adjuntas') §
.
.
.Now to get this to fly I had to change my SPUFI output row maximum, default column width, and output record sizes but finally I had a file with 43,191 INSERTS. As you can see the DECIMAL numbers have a comma in them so I had to do ISPF “change all” commands to change them to full stops and then I had to write a small dynamic SQL program to actually execute these SQLs as they were up to 177 bytes wide…I already had a high-speed version of DSNTIAD that I had written myself a while ago and a simple couple of changes and shazam! I had 43,191 rows of data – the INSERTS took 15 minutes of CPU by the way….
So now I am the proud owner of 43,191 zip codes *and* their spatial “locations” – what could I do? Well the first thing that sprung to mind was – How many cities with how many zip codes are there within a radius of 15 miles of Phoenix, AZ ?
SELECT A.CITY, COUNT(*)
FROM USA.ZIPCODES A
WHERE DB2GSE.ST_WITHIN(A.LOCATION,DB2GSE.ST_BUFFER (
(SELECT B.LOCATION
FROM USA.ZIPCODES B
WHERE B.ZIP = 85009) -- phoenix
, 15 , 'STATUTE MILE')) = 1
GROUP BY A.CITY
;
There are about 73 different spatial functions by the way. In the above SQL I use just two
– ST_BUFFER has three parameters. The first is a “geometry” or LOCATION type field, then a distance, and finally the units. What it does is create a geometry space that is centered on the input geometry and is then the number of units around it (A radius in this case as we have a point as the input geometry). Thus we have a “space” 15 statute miles in radius centered on Phoenix AZ (Well actually on the location of zip code 85009 but that is near enough for me!).
– ST_WITHIN has two parameters which are both “geometries” and if one is within the other it returns a 1 else a 0 thus enabling the simple SQL I wrote.
This query returns:
---------+---------+---------+---------+---------+--------
CITY
---------+---------+---------+---------+---------+--------
Avondale 1
Carefree 1
Cashion 1
Cave Creek 1
Chandler 2
Fountain Hills 1
Gilbert 1
Glendale 12
Laveen 1
Mesa 5
Palo Verde 1
Paradise Valley 1
Peoria 5
Phoenix 71
Scottsdale 8
Sun City 2
Sun City West 1
Surprise 2
Tempe 8
Tolleson 1
Tortilla Flat 1
Wickenburg 1
Youngtown 1
DSNE610I NUMBER OF ROWS DISPLAYED IS 23
DSNE616I STATEMENT EXECUTION WAS SUCCESSFUL, SQLCODE IS 100
Or the same for, say, Moline, IL
SELECT A.CITY, COUNT(*)
FROM USA.ZIPCODES A
WHERE DB2GSE.ST_WITHIN(A.LOCATION,DB2GSE.ST_BUFFER (
(SELECT B.LOCATION
FROM USA.ZIPCODES B
WHERE B.ZIP = 61265) -- moline
, 15 , 'STATUTE MILE')) = 1
GROUP BY A.CITY
;
---------+---------+---------+---------+---------+---------+
CITY
---------+---------+---------+---------+---------+---------+
Andalusia 1
Barstow 1
Bettendorf 1
Blue Grass 2
Buffalo 1
Carbon Cliff 1
Coal Valley 1
Colona 1
Davenport 9
East Moline 1
Eldridge 1
Hampton 1
Le Claire 1
Milan 1
Moline 2
Orion 1
Osco 1
Pleasant Valley 1
Port Byron 1
Preemption 1
Princeton 1
Rapids City 1
Rock Island 5
Sherrard 1
Silvis 1
Taylor Ridge 1
DSNE610I NUMBER OF ROWS DISPLAYED IS 26
Finally I wondered about the distance between two locations or geometries so I thought how many English Chains (I kid you not!) and Miles between these two cities??
SELECT INTEGER(DB2GSE.ST_DISTANCE(
(SELECT B.LOCATION
FROM USA.ZIPCODES B
WHERE B.ZIP = 61265) -- moline
, (SELECT B.LOCATION
FROM USA.ZIPCODES B
WHERE B.ZIP = 85009) -- phoenix
, 'STATUTE MILE')) AS MILES
,INTEGER(DB2GSE.ST_DISTANCE(
(SELECT B.LOCATION
FROM USA.ZIPCODES B
WHERE B.ZIP = 61265) -- moline
, (SELECT B.LOCATION
FROM USA.ZIPCODES B
WHERE B.ZIP = 85009) -- phoenix
, 'BRITISH CHAIN (SEARS 1922)')) AS CHAINS
FROM SYSIBM.SYSDUMMY1
;
---------+---------+---------+---------+-----
MILES CHAINS
---------+---------+---------+---------+-----
1306 104520
DSNE610I NUMBER OF ROWS DISPLAYED IS 1
Isn’t that great! You can even specify which type of chain!!! The Function here ST_DISTANCE just accepts two geometries and the Unit you wish to have output. Just for your reference the number of units are in the GSE view DB2GSE.ST_UNITS_OF_MEASURE the first few rows look like
---------+---------+---------
UNIT_NAME
---------+---------+---------
METRE
FOOT
US SURVEY FOOT
CLARKE'S FOOT
FATHOM
NAUTICAL MILE
GERMAN LEGAL METRE
US SURVEY CHAIN
US SURVEY LINK
US SURVEY MILE
KILOMETRE
CLARKE'S YARD
CLARKE'S CHAIN
CLARKE'S LINK
BRITISH YARD (SEARS 1922)
BRITISH FOOT (SEARS 1922)
BRITISH CHAIN (SEARS 1922)
BRITISH LINK (SEARS 1922)
BRITISH YARD (BENOIT 1895 A)
BRITISH FOOT (BENOIT 1895 A)
BRITISH CHAIN (BENOIT 1895 A)
BRITISH LINK (BENOIT 1895 A)
BRITISH YARD (BENOIT 1895 B)
BRITISH FOOT (BENOIT 1895 B)
BRITISH CHAIN (BENOIT 1895 B)
BRITISH LINK (BENOIT 1895 B)
BRITISH FOOT (1865)
INDIAN FOOT
There is also a handy DESCRIPTION column that explains how and why.
So now I did an EXPLAIN of the three queries (1 is Phoenix, 2 is Moline, and 3 is Distance) and got this
---------+---------+---------+---------+---------+---------+----------+
LINE QNO PNO SQ M TABLE_NAME A CS INDEX IO UJOG UJOGC P CE
---------+---------+---------+---------+---------+---------+----------+
00001 01 01 00 0 ZIPCODES R 00 N ---- ---- S
00001 01 02 00 3 00 N ---- ---Y S
00001 02 01 00 0 ZIPCODES R 00 N ---- ---- S
00002 01 01 00 0 ZIPCODES R 00 N ---- ---- S
00002 01 02 00 3 00 N ---- ---Y S
00002 02 01 00 0 ZIPCODES R 00 N ---- ---- S
00003 01 01 00 0 SYSDUMMY1 R 00 N ---- ---- S
00003 02 01 00 0 ZIPCODES R 00 N ---- ---- S
00003 03 01 00 0 ZIPCODES R 00 N ---- ---- S
00003 04 01 00 0 ZIPCODES R 00 N ---- ---- S
00003 05 01 00 0 ZIPCODES R 00 N ---- ---- S
-----+---------+---------+---------+---------+---------+-----------+
QUERYNO PROGNAME STMT_TYPE CC PROCMS PROCSU REASON
-----+---------+---------+---------+---------+---------+-----------+
1 DSNESM68 SELECT B 327 929 TABLE CARDINALITY UDF
2 DSNESM68 SELECT B 327 929 TABLE CARDINALITY UDF
3 DSNESM68 SELECT B 676 1918 TABLE CARDINALITY UDF
No big surprises as I have not run a RUNSTATS and have not created any indexes yet.
So now a full runstats and a re-explain
---------+---------+---------+---------+---------+---------+---------+-
LINE QNO PNO SQ M TABLE_NAME A CS INDEX IO UJOG UJOGC P CE
---------+---------+---------+---------+---------+---------+---------+-
00001 01 01 00 0 ZIPCODES R 00 N ---- ---- S
00001 01 02 00 3 00 N ---- ---Y S
00001 02 01 00 0 ZIPCODES R 00 N ---- ---- S
00002 01 01 00 0 ZIPCODES R 00 N ---- ---- S
00002 01 02 00 3 00 N ---- ---Y S
00002 02 01 00 0 ZIPCODES R 00 N ---- ---- S
00003 01 01 00 0 SYSDUMMY1 R 00 N ---- ---- S
00003 02 01 00 0 ZIPCODES R 00 N ---- ---- S
00003 03 01 00 0 ZIPCODES R 00 N ---- ---- S
00003 04 01 00 0 ZIPCODES R 00 N ---- ---- S
00003 05 01 00 0 ZIPCODES R 00 N ---- ---- S
-----+---------+---------+---------+---------+---------+---------+----
QUERYNO PROGNAME STMT_TYPE CC PROCMS PROCSU REASON
-----+---------+---------+---------+---------+---------+---------+----
1 DSNESM68 SELECT B 2427 6893 UDF
2 DSNESM68 SELECT B 2427 6893 UDF
3 DSNESM68 SELECT B 676 1918 TABLE CARDINALITY UDF
The MS and SU numbers went up as now the optimizer realized the size of the table. So now I created a unique index on column ZIP
CREATE UNIQUE INDEX USA.ZIPCODES_IX ON USA.ZIPCODES (ZIP ASC) USING STOGROUP SYSDEFLT PRIQTY 720 SECQTY 720 CLUSTER FREEPAGE 0 PCTFREE 10 CLOSE YES;
Run RUNSTATs and re-explained
---------+---------+---------+---------+---------+---------+---------+----
LINE QNO PNO SQ M TABLE_NAME A CS INDEX IO UJOG UJOGC P CE
---------+---------+---------+---------+---------+---------+---------+-----
00001 01 01 00 0 ZIPCODES R 00 N ---- ---- S
00001 01 02 00 3 00 N ---- ---Y S
00001 02 01 00 0 ZIPCODES I 01 ZIPCODES_IX N ---- ----
00002 01 01 00 0 ZIPCODES R 00 N ---- ---- S
00002 01 02 00 3 00 N ---- ---Y S
00002 02 01 00 0 ZIPCODES I 01 ZIPCODES_IX N ---- ----
00003 01 01 00 0 SYSDUMMY1 R 00 N ---- ---- S
00003 02 01 00 0 ZIPCODES I 01 ZIPCODES_IX N ---- ----
00003 03 01 00 0 ZIPCODES I 01 ZIPCODES_IX N ---- ----
00003 04 01 00 0 ZIPCODES I 01 ZIPCODES_IX N ---- ----
00003 05 01 00 0 ZIPCODES I 01 ZIPCODES_IX N ---- ----
-----+---------+---------+---------+---------+---------+-------+--------
QUERYNO PROGNAME STMT_TYPE CC PROCMS PROCSU REASON
-----+---------+---------+---------+---------+---------+-------+--------
1 DSNESM68 SELECT B 2427 6893 UDF
2 DSNESM68 SELECT B 2427 6893 UDF
3 DSNESM68 SELECT B 676 1918 TABLE CARDINALITY UDFAha! My index is being used but the cost estimates did not change a bit! So now is the time for a Spatial Index to rear its ugly head and get involved. Now a spatial index is a very, very special type of beast. It is *not* a standard B-Tree style index and it exists “outside” the scope of normal DB2 Indexes. Now to create a SPATIAL INDEX you must use a stored procedure with a bunch of parameters:
sysproc.ST_create_index ( table_schema/NULL, table_name , column_name , index_schema/NULL, index_name , other_index_options/NULL, grid_size1 , grid_size2 , grid_size3 , msg_code , msg_text )
I am actually using the command processor DSN5SCLP so my syntax looks like:
DSN5SCLP /create_idx ZA00QA1A +
-tableschema USA -tablename ZIPCODES -columnname LOCATION +
-indexschema USA -indexname LOC_IX +
-otherIdxOpts "FREEPAGE 0" +
-gridSize1 1.0 -gridSize2 2.0 -gridSize3 3.0
When it executes it just tells you this:
********************************* TOP OF DATA *****
GSE0000I The operation was completed successfully.
******************************** BOTTOM OF DATA ***
Now do a re-explain
---------+---------+---------+---------+---------+---------+---------+--
LINE QNO PNO SQ M TABLE_NAME A CS INDEX IO UJOG UJOGC P CE
---------+---------+---------+---------+---------+---------+---------+--
00001 01 01 00 0 ZIPCODES I 01 LOC_IX N ---- ----
00001 01 02 00 3 00 N ---- ---Y S
00001 02 01 00 0 ZIPCODES I 01 ZIPCODES_IX N ---- ----
00002 01 01 00 0 ZIPCODES I 01 LOC_IX N ---- ----
00002 01 02 00 3 00 N ---- ---Y S
00002 02 01 00 0 ZIPCODES I 01 ZIPCODES_IX N ---- ----
00003 01 01 00 0 SYSDUMMY1 R 00 N ---- ---- S
00003 02 01 00 0 ZIPCODES I 01 ZIPCODES_IX N ---- ----
00003 03 01 00 0 ZIPCODES I 01 ZIPCODES_IX N ---- ----
00003 04 01 00 0 ZIPCODES I 01 ZIPCODES_IX N ---- ----
00003 05 01 00 0 ZIPCODES I 01 ZIPCODES_IX N ---- ----
-----+---------+---------+---------+---------+---------+---------+-----
QUERYNO PROGNAME STMT_TYPE CC PROCMS PROCSU REASON
-----+---------+---------+---------+---------+---------+---------+----
1 DSNESM68 SELECT B 2 5 UDF
2 DSNESM68 SELECT B 2 5 UDF
3 DSNESM68 SELECT B 676 1918 TABLE CARDINALITY UDF
BINGO! Looks like a winner to me!
Now a RUNSTATS and a re-explain
DSNU000I 200 09:00:34.20 DSNUGUTC - OUTPUT START FOR UTILITY, UTILID = RUNSTATS
DSNU1044I 200 09:00:34.35 DSNUGTIS - PROCESSING SYSIN AS EBCDIC
DSNU050I 200 09:00:34.37 DSNUGUTC - RUNSTATS TABLESPACE ZIPCODES.ZIPCODES TABLE(ALL) INDEX(ALL KEYCARD)
SHRLEVEL REFERENCE UPDATE ALL SORTDEVT SYSALLDA SORTNUM 4
DSNU186I -QA1A 200 09:00:34.39 DSNUGSRI - A SPATIAL INDEX CANNOT BE PROCESSED BY THIS UTILITY
DSNU012I 200 09:00:34.41 DSNUGBAC - UTILITY EXECUTION TERMINATED, HIGHEST RETURN CODE=8
Argghhh! That was *not* in the documentation!!! So not just LOAD dies but also RUNSTATS!! The message itself is *very* helpful:
DSNU186I csect-name– A SPATIAL INDEX CANNOT BE PROCESSED BY THIS UTILITY
Explanation: The target objects specified for the utility include one or more spatial indexes, which are not supported by this utility. If the utility specifies a table space, then you can drop the spatial indexes, run the utility, and then recreate the indexes.
System action: The utility does not execute.
Severity: 8
I will try a REORG just for fun…nope it dies as well. Looks like you must remember to DROP all spatial indexes before any ”normal” DB2 Database Maintenance and then CREATE them back afterwards. Or if you have our RealTimeDatabaseExpert you can simply Exclude them from processing.
Finally this month a few CPU statistics from before and after index creation:
| Query | Without Spatial Index | With Spatial Index |
| Elapsed | CPU | Elapsed | CPU |
Phoenix Query
Moline Query
Distance | 202 seconds
186 seconds
2 | 186 seconds
172
1 | 25 seconds
13
2 | 23 seconds
9
1 |
Note that these figures are for 100 times execution in batch. As can be seen use of Spatial Indexes is very very good!
Well I learnt a lot this month and hope some of you did as well – As usual any comments or questions please feel free to mail me!