Each month, SEG sends out valuable technical DB2 z/OS information based on knowledge gained by the experienced developers and technicians in our product labs. We would like to share this newsletter with other DB2 users, like yourself.
This month, I want to go through some of the absolutely most important ZPARMs that control how your Db2 systems behave in a very significant manner. All of the following ZPARMs have a performance impact of some sort. We are always trying to squeeze the last drop of performance out of our Db2 sub-systems, aren’t we?
Db2 13 and Some Db2 12 Updates Ahead!
Since this Newsletter topic first came out, in March 2022, out of the ten ZPARMs listed *five* have got new defaults! I have highlighted all these changed defaults. I have also added three new „Usual Suspects“ to the list of ZPARMs that must be checked…
Starting with the Easy Stuff…
CACHEDYN. YES/NO, default YES. Should always be set to YES – unless you do not care about saving dynamic SQL performance. Back a few decades ago, the recommendation was to have this set to NO as default! Hard to believe that these days, where most shops have 80% – 90% dynamic SQL during the day!
Now we Get to the Numerics!
OUTBUFF. 400 – 400,000, default 102,400. This is *extremely* important and you really should set it to the highest possible value you can afford in real memory! As a minimum, it should be 102,400 KB (100MB). This is the buffer that Db2 uses to write log records before they are „really“ written to disk. The larger the buffer, the greater the chance that, in case of a ROLLBACK, the data required is in the buffer and not on disk.
Skeletons in the Closet?
EDM_SKELETON_POOL. 5,120 – 4,194,304, default 81,920. This is one of my personal favorites, (I wrote a newsletter solely on this a few years ago). I personally recommend at least 150,000 KB and actually even more if you can back it with real memory. Just like OUTBUFF, pour your memory in here but keep an eye on paging! If Db2 starts to page, you are in serious trouble! Raising this can really help with keeping your DSC in control.
DBDs are Getting Bigger…
EDMDBDC. 5,000 – 4,194,304, default 40,960. The DBD Cache is getting more and more important as, due to UTS usage, the size of DBDs is increasing all the time.
DSC is Always Too Small!
EDMSTMTC. 5,000 – 4,194,304, default 113,386. The EDM Statement Cache (really the Dynamic Statement Cache) is where Db2 keeps a copy of the prepared statements that have been executed. So when the exact same SQL statement with the exact same set of flags and qualifiers is executed, Db2 can avoid the full prepare and just re-execute the statement. This is basically a no-brainer and should be set to at least 122,880 KB. Even up to 2TB is perfectly OK. Remember: A read from here is *much* faster than a full prepare, so you get a very quick ROI and great value for the memory invested! Keep raising the value until your flushing rates for DSC drop down to just 100’s per hour, if you can! Remember to cross check with the EDM_SKELETON_POOL ZPARM as well. It always takes two to Tango…
How Many SQLs?
MAXKEEPD. 0 – 204,800, default 5,000. The Max Kept Dyn Stmts parameter is how many prepared SQLs to keep past commit or rollback. It should be set to a minimum of 8,000 or so. Raising this might well cause a large memory demand in the ssidDBM1 address space so care must be taken.
RIDs Keep Getting Longer…
MAXRBLK. 0, 128 – 2,000,000, default 1,000,000. RID POOL SIZE is the maximum amount of memory to be available for RID Block entries. It should be at least 1,000,000 and, if you can, push it to the maximum of 2,000,000. Unless you want to switch off all RID Block access plans, in which case you set it to zero – Obviously not really recommended!
Sorts Always Need More Space
MAXSORT_IN_MEMORY. 1000 to SRTPOOL. Default 2000. The maximum in-memory sort size is the largest available space to complete ORDER BY, GROUP BY or both SQL Clauses. Remember that this is per thread, so you must have enough memory for lots of these in parallel. The number should be between 1,000 and 2,000, but whatever value you choose, it must be less than or equal to the SRTPOOL size.
Sparse or Pair-wise Access?
MXDTCACH. 0 – 512, default 20. Max data caching is the maximum size of the sparse index or pair-wise join data cache in megabytes. If you do not use sparse index, pair-wise join, or you are not a data warehouse shop, then you can leave this at its default. Otherwise, set it to be 41 MB or higher. If it is a data warehouse subsystem, then you could set this as high as 512 MB. (This ZPARM replaced the short-lived SJMXPOOL, by the way.)
Sort Node Expansion
SRTPOOL. 240 – 128,000, default 20,000. SORT POOL SIZE is the available memory that is needed for the sort pool. IFCID 96 can really help you size this parameter. Remember that the number of sort nodes leapt up from 32,000 in Db2 11 to 512,000 nodes for non-parallelism sorts and 128,000 nodes for a sort within a parallel child task in Db2 12. This means raising this ZPARM can have an even greater positive effect than before.
The Three New Guys on the Block!
To the MAX!
DSMAX used to be around 20,000 and can now be between 1 – 400,000. Remember that you will never actually reach this maximum limit as it is 31-bit memory-constrained.
Thrashing Around…
NPGTHRSH. Valid values are 0 or 1 – 2147483647. Default up to Db2 11 was 0, from Db2 12 default is now 1. SAP systems use a default of 10. The big change here, was in Db2 12 when the change from „no statistics ever ran“ of -1 forced the value to be the „optimizer default“ of 501 instead of the real value -1. This is also why the default is now 1 ,so that this ZPARM has a normal use! Setting it to 0 means that the access path chosen will always only be cost based.
Lock ‚em Up and Throw Away the Key!
NUMLKUS. 0 – 104857600, with a default of 20,000. Just be careful raising this value too high, as each lock will take 540 bytes of storage in the IRLM!
Your „Top Ten List“ + Three
These thirteen ZPARMs really influence how your Db2 system works and so must always be checked and changed with great care and attention to detail. Always do a before and after appraisal to see whether or not changing them helped or hindered your system!
If you have any comments, or other ZPARMs you think are also important for performance, feel free to drop me a line!
IDUG 2023 NA
IDUG is nearly upon again. I will be there in Philadelphia at the SEGUS booth and doing a fair bit of moderating as well. Drop on by, have a chat and pick up some of our swag and join me at the „Roy reviews AI with our WorkloadExpert“ PSP on Thursday for a chance to win some cool stuff.
Hi! Continuing on with my AI blog (last one. I promise!) I wish to delve into the innards of the USS part of the SQL Data Insights experience and show you what it all costs!
A Quick Review Perhaps?
Please check my older newsletters for everything about install etc. of SQL DI, and one important thing which is the latest Vector Prefetch APARs (also see my last newsletter for details). Now. I will be doing „before and after“ performance reviews with this feature on and off.
Bad News First!
What I have found, is that when I take a 500,000 row table into SQL DI and choose 17 columns, it takes the *entire* machine as well as all local page datasets and I was forced to cancel it after five hours…
Looking in the Logs…
If you go trawling around your Unix Directories, you will trip over these paths:
/u/work/sqldi
Home is Where the Spark is!
This is “home” where all of the SQL DI stuff is “installed”, naturally your name might be different!
Under here is the next layer of interest to me for the Spark processing.
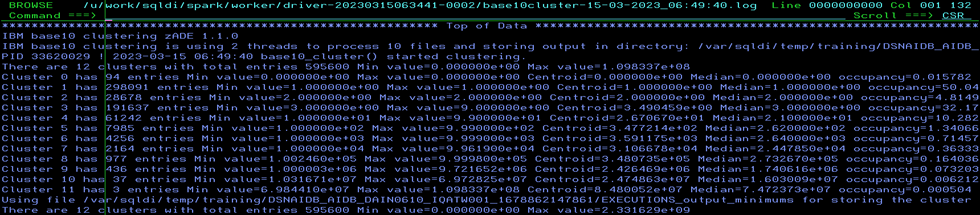
It is Magic!
/u/work/sqldi/spark – Now this is where Spark does “the magic” and actually computes all your vector table data. It runs in stages and the first is the Base10 (I guess numeric analysis) part. For my test data it looks like this:
Scroll down to the bottom:
So, this ran really quickly!
Internals…
Then it does a ton of internal stuff and it starts actually doing the learning, which is “progressed” in a file like this:
Just Sitting There, Typing REF and Pressing ENTER…
Of course your name will be different, but just sitting there in OMVS and using the REF command you will see this file grow in size every now and again. When it does, quickly Browse on in and you will see stuff like this:
ibm-data2Vec (1.1.0 for zOS) starting execution using file /var/sqldi/temp/training/DSNAIDB_AIDB_DAI
ibm-data2vec found the required library: libzaio.so. Proceeding with the training..
ibm-data2vec will use following mode: CBLAS
User has not provided training chunk size. Using 1 GB chunk size for reading training file.
ibm-data2Vec is preallocating space for the model using user-provided value 1230314
ibm-data2Vec starting execution using file /var/sqldi/temp/training/DSNAIDB_AIDB_DAIN0610_IQATW001_1
83951683 ! 2023-03-15 07:17:27 ! Time elapsed learning vocab from train file = 145.91525s
Processed 13103200 words in the training file. There are 1213852 unique words in the vocabulary: Pri
Model training code will generate vectors for row-identifier (pk_id) or user-specified primary keys
83951683 ! 2023-03-15 07:17:27 ! Stage 1 completed. Time elapsed during file reading = 145.91643s
Training the database embedding (db2Vec) model using 12 CPU thread(s)
Whole Machine Gone – Oh Oh!
Now, in my case, it just sat there for a while taking all paging, all frames, all ziip and cp cpu and then it wrote out:
Epoch 0 learning rate Alpha=0.024704 Training Progress=5.00%
Epoch 0 learning rate Alpha=0.024404 Training Progress=10.00%
Epoch 0 learning rate Alpha=0.024099 Training Progress=15.00%
Epoch 0 learning rate Alpha=0.023791 Training Progress=20.00%
Epoch 0 learning rate Alpha=0.023486 Training Progress=25.00%
Epoch 0 learning rate Alpha=0.023182 Training Progress=30.00%
Epoch 0 learning rate Alpha=0.022885 Training Progress=35.00%
Epoch 0 learning rate Alpha=0.022582 Training Progress=40.00%
Epoch 0 learning rate Alpha=0.022286 Training Progress=45.00%
Epoch 0 learning rate Alpha=0.021980 Training Progress=50.00%
Epoch 0 learning rate Alpha=0.021673 Training Progress=55.00%
That last line was written out at 12:42 and after starting at 07:17 you can see that I still had nearly a five hour wait ahead of me. Time to cancel and rethink this!
Restart!
Thankfully, on the GUI interface (where you cannot see this progress info, sadly!) the “Stop training” button worked after a while. If it does not respond then you can just issue the
S SQLDAPPS,OPTION='SQLDSTOP'
command to stop it. Then, once all stopped, and the cpus have cooled down a bit, you can select a smaller data set and retry learning!
Smaller is Sometimes Better!
And with 40.000 rows it is much faster:
50397300 ! 2023-03-15 12:17:16 ! Stage 1 completed. Time elapsed during file reading = 26.992490s
Training the database embedding (db2Vec) model using 12 CPU thread(s)
Epoch 0 learning rate Alpha=0.024765 Training Progress=5.00%
Epoch 0 learning rate Alpha=0.024539 Training Progress=10.00%
Epoch 0 learning rate Alpha=0.024308 Training Progress=15.00%
Epoch 0 learning rate Alpha=0.024073 Training Progress=20.00%
Epoch 0 learning rate Alpha=0.023826 Training Progress=25.00%
Epoch 0 learning rate Alpha=0.023591 Training Progress=30.00%
Epoch 0 learning rate Alpha=0.023354 Training Progress=35.00%
Epoch 0 learning rate Alpha=0.023115 Training Progress=40.00%
Epoch 0 learning rate Alpha=0.022878 Training Progress=45.00%
Epoch 0 learning rate Alpha=0.022637 Training Progress=50.00%
Epoch 0 learning rate Alpha=0.022406 Training Progress=55.00%
Naturally, this is heavily dependent on the machine you have, the memory you have and the size of your local paging dataset.
EXPLAIN Yourself!
So now to do some EXPLAIN runs and then a quick comparison of the “double” AI Whammy that I have, quickly followed by the “New” PTF that, hopefully, sorts it all out.
Double Trouble?
You might have noticed that in my test SQLs I have to use the BiF AI twice. Once for the SELECT and once for the WHERE. This is because the use of the AI_VALUE column is not supported in the WHERE predicate.
Naturally, you can re-write the query to look like this:
SELECT * FROM
(SELECT AI_SEMANTIC_CLUSTER( PROGRAM,
'DSNTIAUL',
'DSN§EP2L',
'DSN§EP4L') AS AI_VALUE
,A.WLX_TIMESTAMP
,A.STMT_ID
,A.STMT_TIMESTAMP
,SUBSTR(A.PRIM_AUTHOR , 1 , 8) AS PRIM_AUTHOR
,SUBSTR(A.PROGRAM , 1 , 8) AS PROGRAM
,SUBSTR(A.REF_TABLE , 1 , 18) AS REF_TABLE
,A.EXECUTIONS
,A.GETP_OPERATIONS
,A.ELAPSE_TIME
,A.CPU_TIME
,A.STMT_TEXT
FROM DAIN0610.IQATW001 A
WHERE 1 = 1
AND A.PROGRAM NOT IN ('DSNTIAUL',
'DSN§EP2L',
'DSN§EP4L')
AND A.STMT_ORIGIN = 'D'
)
WHERE AI_VALUE IS NOT NULL
ORDER BY 1 DESC -- SHOW BEST FIRST
--ORDER BY 1 -- SHOW WORST FIRST
FETCH FIRST 10 ROWS ONLY ;
Does My Work File Look Big to You?
The problem is that now you have a HUGE work file… In my tests it was always much quicker to code the AI BiF twice. After all, it is always „Your Mileage May Vary“, „The Cheque is in the post“ or „It depends“, isn’t it?
AI Does Use the Optimizer!
EXPLAIN Output… The AI Does indeed get output by EXPLAIN (I was surprised about this to be honest!) for the following query:
SELECT AI_SEMANTIC_CLUSTER( PROGRAM,
'DSNTIAUL',
'DSN§EP2L',
'DSN§EP4L') AS AI_VALUE
,A.WLX_TIMESTAMP
,A.STMT_ID
,A.STMT_TIMESTAMP
,SUBSTR(A.PRIM_AUTHOR , 1 , 8) AS PRIM_AUTHOR
,SUBSTR(A.PROGRAM , 1 , 8) AS PROGRAM
,SUBSTR(A.REF_TABLE , 1 , 18) AS REF_TABLE
,A.EXECUTIONS
,A.GETP_OPERATIONS
,A.ELAPSE_TIME
,A.CPU_TIME
,A.STMT_TEXT
FROM DAIN0610.IQATW001 A
WHERE 1 = 1
AND A.PROGRAM NOT IN ('DSNTIAUL',
'DSN§EP2L',
'DSN§EP4L')
AND AI_SEMANTIC_CLUSTER( PROGRAM,
'DSNTIAUL',
'DSN§EP2L',
'DSN§EP4L')
IS NOT NULL
AND A.STMT_ORIGIN = 'D'
ORDER BY 1 DESC -- SHOW BEST FIRST
--ORDER BY 1 -- SHOW WORST FIRST
FETCH FIRST 10 ROWS ONLY ;
The EXPLAIN output looks like:
Then it gets an interesting STAGE2 RANGE predicate!
which resolves into:
So here we see what the BiF is doing from the perspective of the Optimizer! If you run the nested table version of the query then this line does *not* appear at all!
Notice here that the RANGE is now a STAGE1!
Optimize This!
So IBM Db2 has incorporated it into the Optimizer which is a good thing. But please remember: your SQL can have local predicates that cut down the size of the work file and so evens out the access times… Basically, you must code both and test to see which of the solutions is better for typical usage (As always really…)
Time, Measure, Repeat
Ok, now just doing one execute of the double query requires 2.58 seconds of CPU and 15.35 seconds elapsed. The statement is *in* the DSC so prepare time can be ignored. Here you can see it has been executed twice so we have average values but I am using the CPU from the batch job as it is more precise.
Changing the query to now fetch back all rows instead of first ten requires 7.06 seconds of CPU and 48.78 seconds elapsed. But it returned over 200K rows!
While the query was running you can see the SQLD SQL DI in SDSF taking quite large chunks of zIIP time…
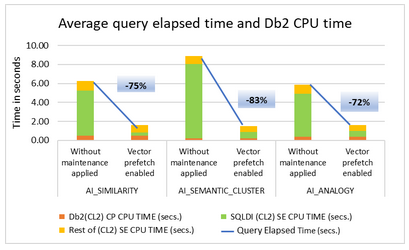
Now I will enable Vector Prefetch with a value of 10GB to see if it makes an impact for these queries. To do this you must update the ZPARM MXAIDTCACH and then enable the changed ZPARM.
That is Not What I was Expecting!
First query is now 2.56 CPU and 15.26 Elapsed. More like background noise than an improvement. And now with the FETCH FIRST removed 7.07 and 49.36 seconds. I guess my queries are not improved with Vector Prefetch!
Could be Me…
From the IBM Vector Prefetch docu:
With vector prefetch enabled, CPU performance for AI queries with AI function invocation on qualified rows improves particularly when the ratio of the cardinality of qualified rows to the total number of numeric vectors for the column is high.
Now let’s try and see if I can discover something new in real data! Anything sensitive has been obfuscated!
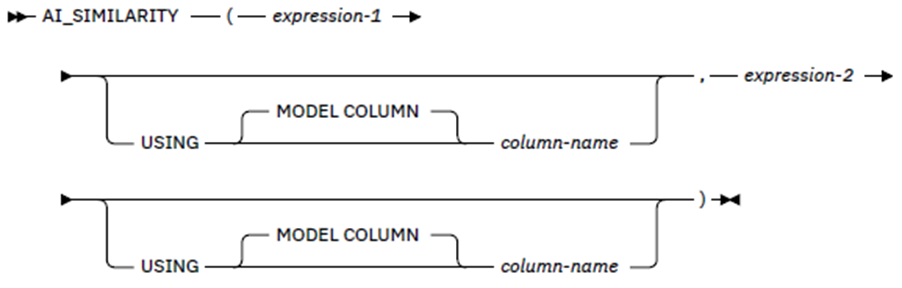
SELECT AI_SIMILARITY( PROGRAM,
'IQADBACP') AS AI_VALUE
,SUBSTR(A.PRIM_AUTHOR , 1 , 8) AS PRIM_AUTHOR
,SUBSTR(A.PROGRAM , 1 , 8) AS PROGRAM
,SUBSTR(A.REF_TABLE , 1 , 18) AS REF_TABLE
,A.WLX_TIMESTAMP
,A.STMT_ID
,A.STMT_TIMESTAMP
,A.EXECUTIONS
,A.GETP_OPERATIONS
,A.ELAPSE_TIME
,A.CPU_TIME
,A.STMT_TEXT
FROM DAIN0610.IQATW001 A
WHERE 1 = 1
AND NOT A.PROGRAM = 'IQADBACP'
AND AI_SIMILARITY ( PROGRAM,
'IQADBACP')
IS NOT NULL
AND A.STMT_ORIGIN = 'D'
ORDER BY 1 DESC -- SHOW BEST FIRST
--ORDER BY 1 -- SHOW WORST FIRST
FETCH FIRST 10 ROWS ONLY;
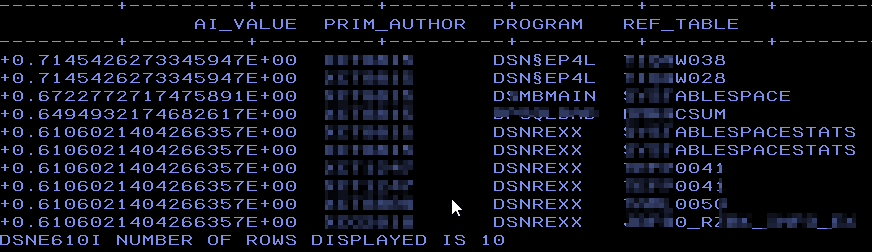
This is similar to my test from last month but now on real data. Note that I have added a predicate A.STMT_ORIGIN = ‚D‘ as I only want Dynamic SQL programs:
Dynamic Hits?
Here you can see that it has found a variety of programs that also do dynamic SQL but I also „helped“ it by only asking for dynamic SQL. So now once again but this time without the predicate A.STMT_ORIGIN = ‚D‘:
Success!
It has found nearly all from the first list but also different ones, crucially it has *not* found any Static SQL!
So, that’s enough of AI for the next few months for me. However, if you have any questions or ideas that I could try out feel free to email!
OK, I kept you all waiting long enough… Here are my AI results with Db2 13 FL501!
Start at the Start
We begin with the beginning as last time:
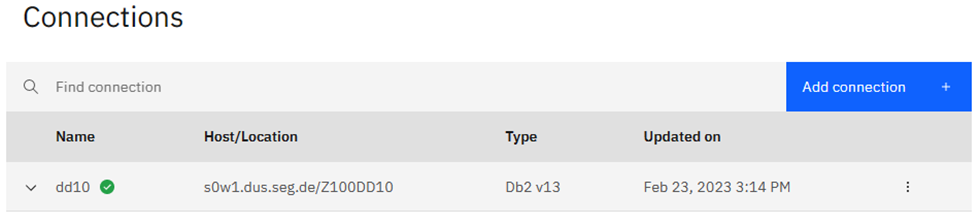
Let’s get Connected!
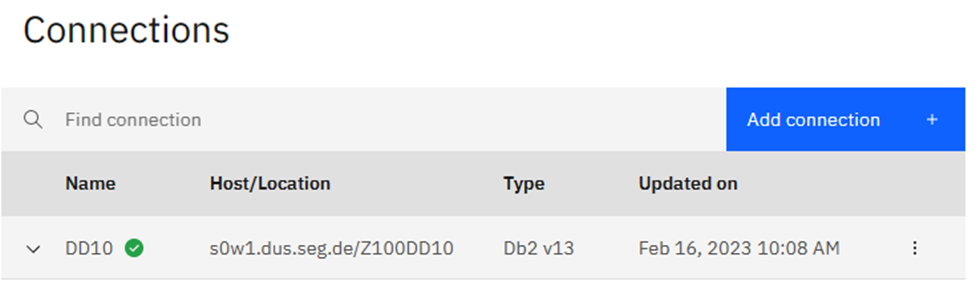
Here you can see that I have already defined my little test Db2 13 system to the system:
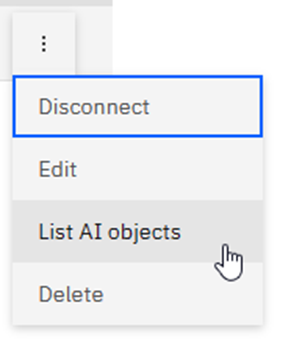
Join the Dots …
Now just click on the vertical dots:
Here you can Disconnect, Edit (Which shows you the same window as “add connection”), List AI objects or Delete.
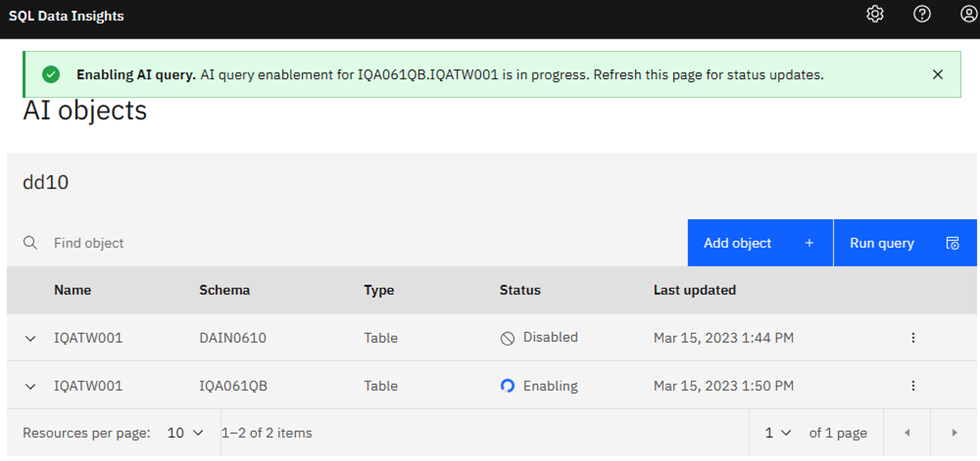
What do we have?
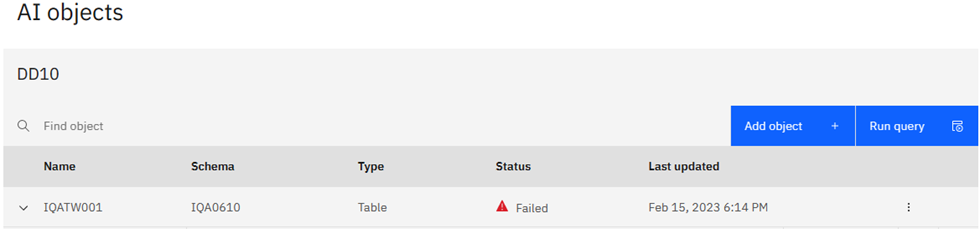
Choosing List AI objects you see what has been created:
Clicking on the down arrow on the left-hand side to expand looks a lot better than last month:
Clickedy-click-click
Now, clicking on the vertical dots on the right hand side, you can choose to Disable AI query or Enable AI query. (I have actually added a new column for consideration, so first I clicked on Disable and then clicked again on Enable)
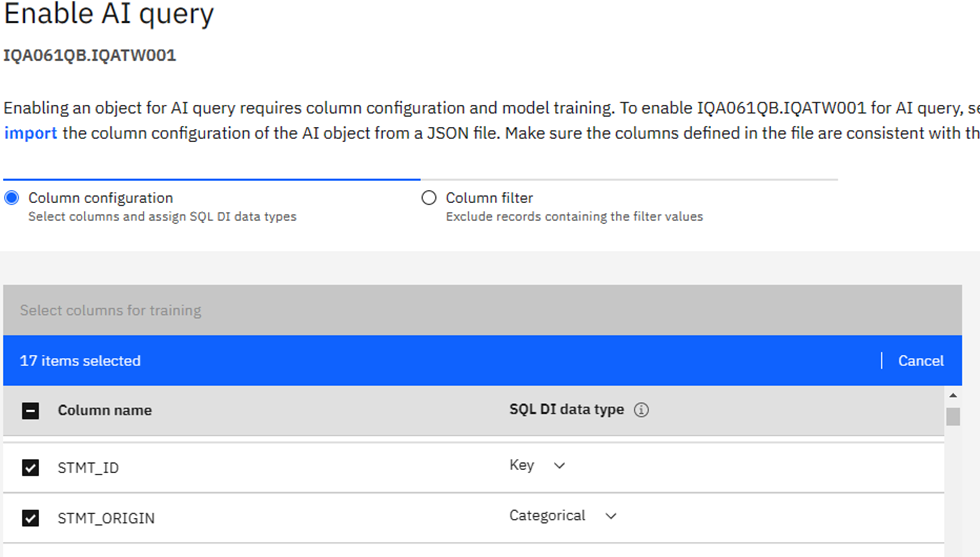
Just the Facts, Ma’am – Again
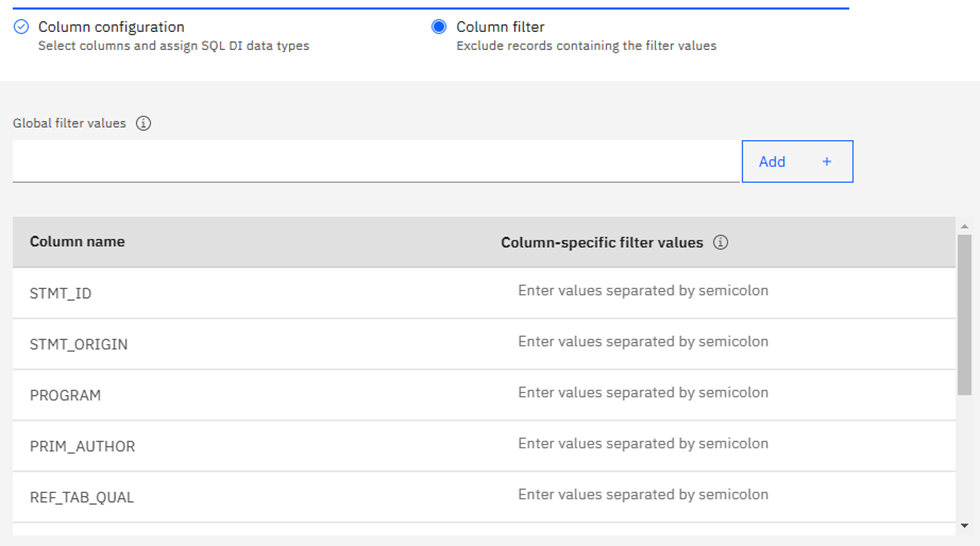
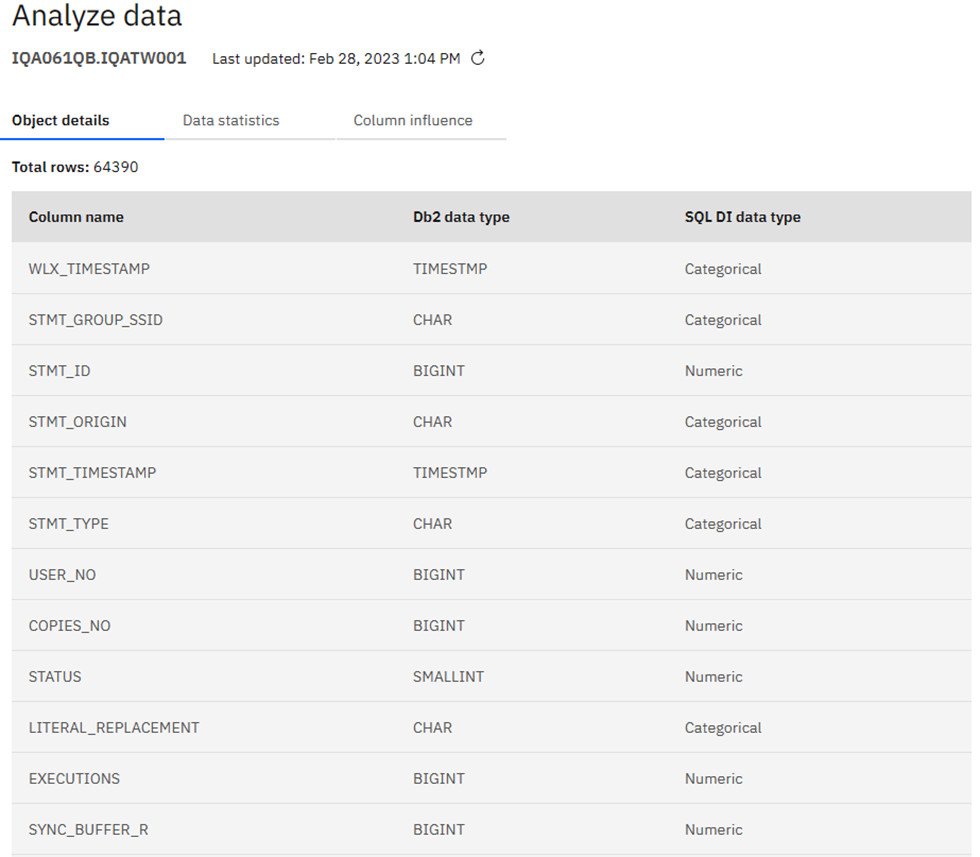
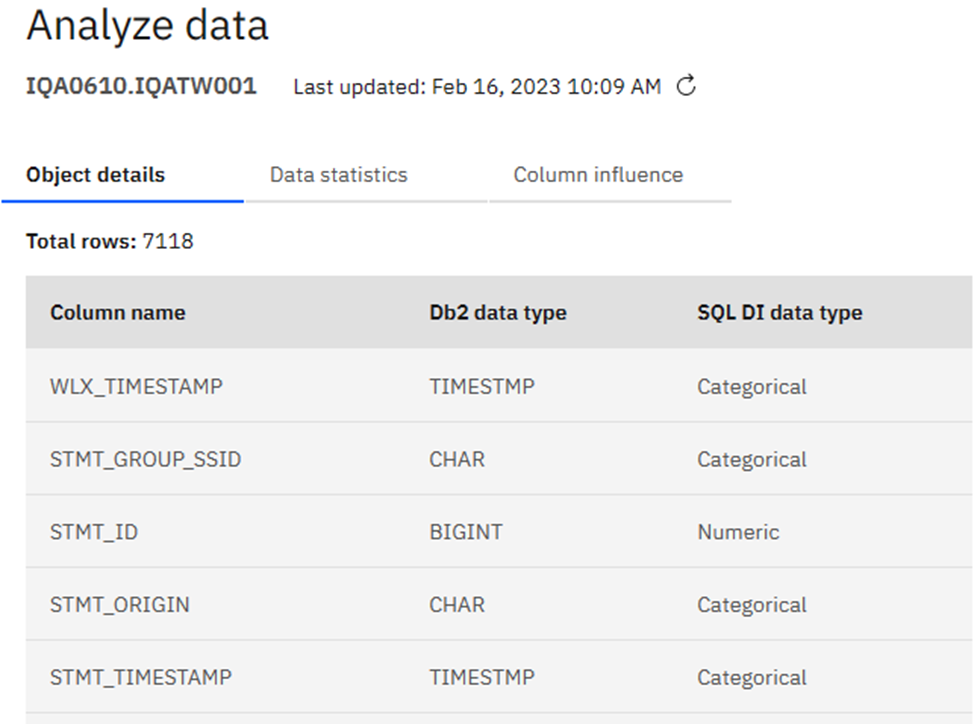
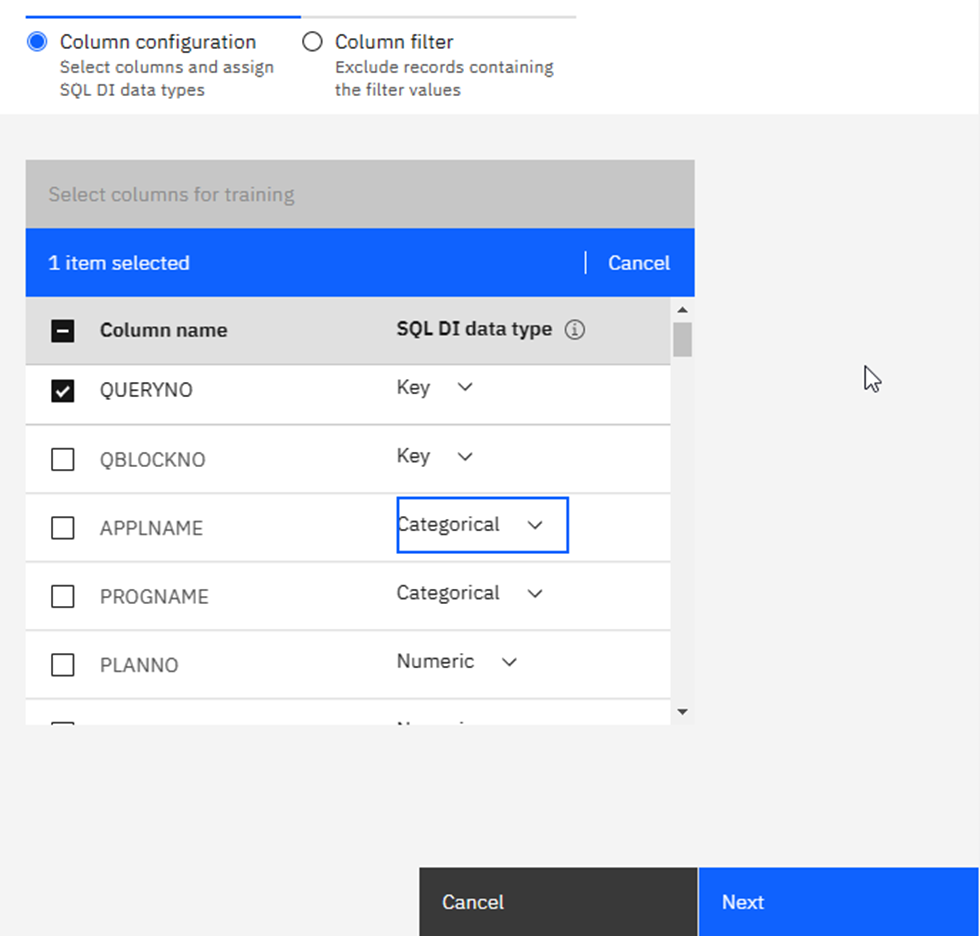
Here you must make your “Usual Suspects” decision: which columns to actually use in building the AI Model. I am using our WorkLoadExpert performance table in this newsletter and have selected 17 columns that I think will work together nicely. Only one can be a “Key” column – I choose STMT_ID in this case. Once you are done selecting columns, click on the big blue “Next” button where you may then add additional filters to remove any rows you know are to be ignored:
Playing Chicken?
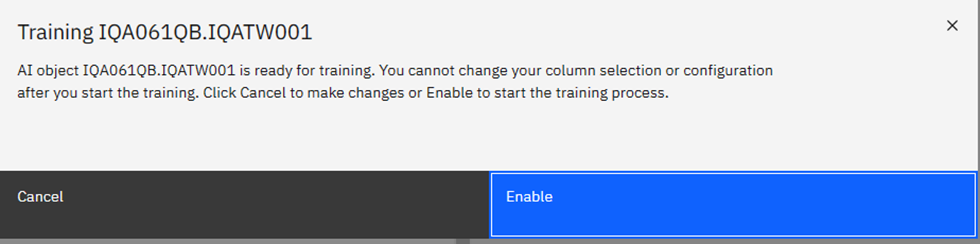
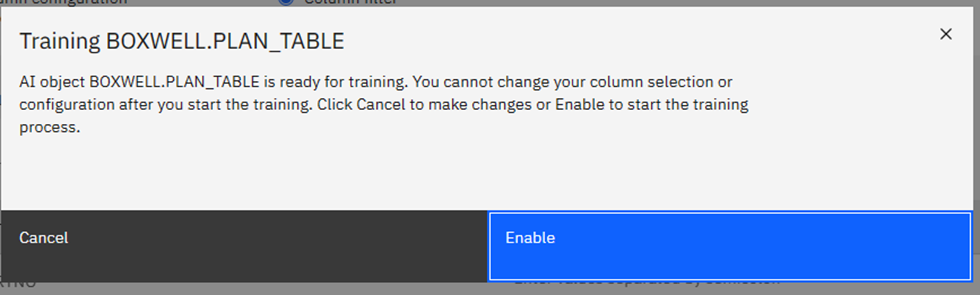
When done, click on the big blue “Enable” button and you get your last chance to chicken out:
SIO and CPU Records!
Click here and then get a cup of coffee….or go to SDSF and marvel at how much CPU and IO Spark actually uses and does this as the light bulbs dim in your part of the world…
You Keep me Spinning
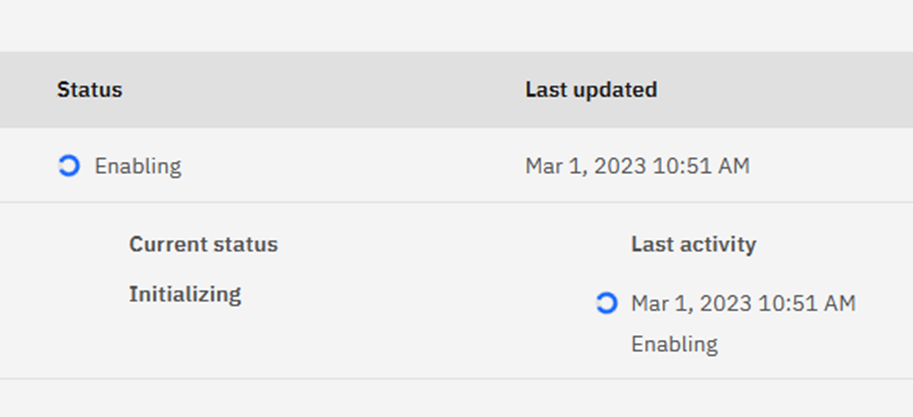
Oddly, at least when I do this, the Initializing spinning wheels:
Right Round and Around
… never stop. The WLM Stored procedure for utilities was finally kicked off about 40 minutes later:
J E S 2 J O B L O G -- S Y S T E M
10.43.19 STC09611 ---- WEDNESDAY, 01 MAR 2023 ----
10.43.19 STC09611 $HASP373 DD10WLMU STARTED
10.43.19 STC09611 IEF403I DD10WLMU - STARTED - TIME=10.43.19
10.43.19 STC09611 ICH70001I SQLDIID LAST ACCESS AT 09:37:37
A Loaded Question?
And loaded all the required data:
ICE134I 0 NUMBER OF BYTES SORTED: 99083595
ICE253I 0 RECORDS SORTED - PROCESSED: 49173, EXPECTED: 49173
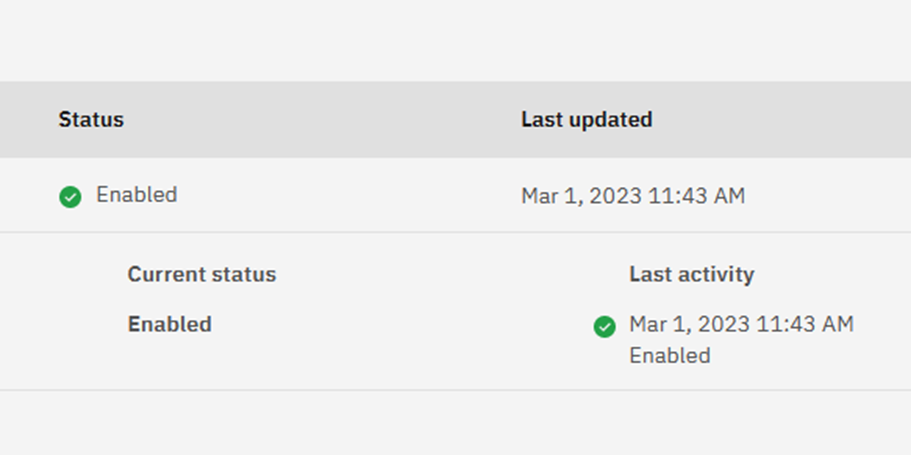
A quick exit and re-logon to the web interface…and Tra la!
Not only AI but Dr Who!
It is also strange that it seems to be in a time machine, one hour in advance of my local…Anyways, my new data is there and so onward! (I have since heard that our time zone setting is actually to blame and that just going back one level, and then forward again, stops the spinning wheel problem. However, just wait until Spark finishes and the stored procedure has loaded your data!)
Never Trust a Statistic You haven’t Faked Yourself!
Clicking on Data statistics shows:
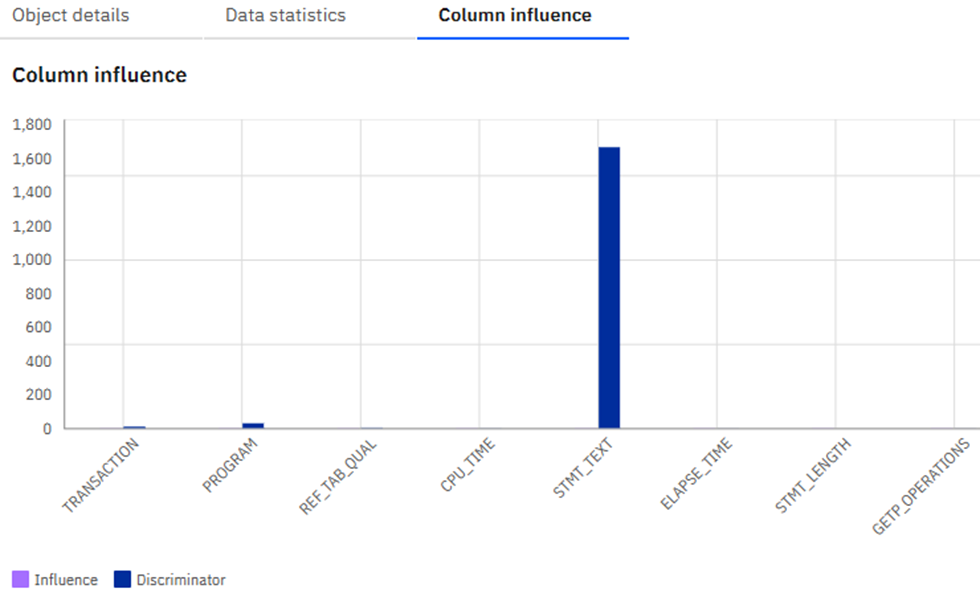
Influencer of the Day?
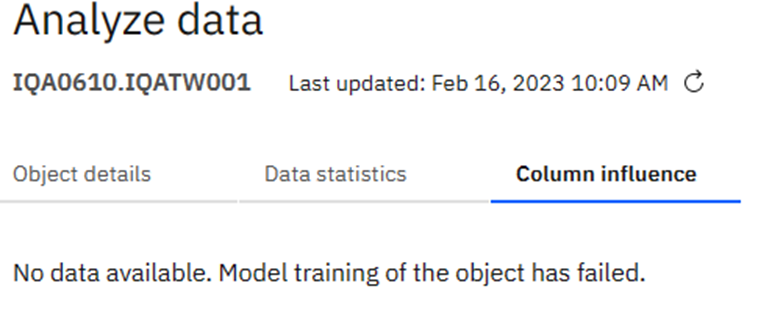
Then you can look at the Column influence:
Super Model?
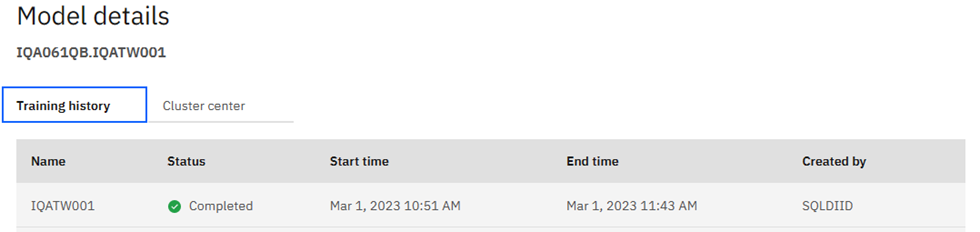
Back at the top you can then review the Model details:
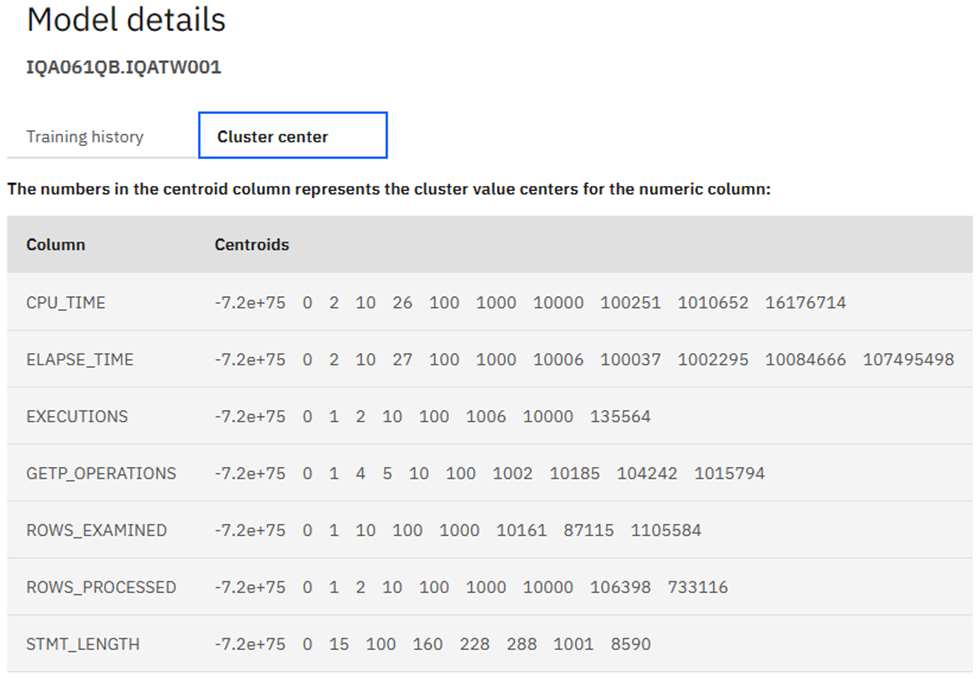
Or just a Cluster….
Here are the Cluster center details:
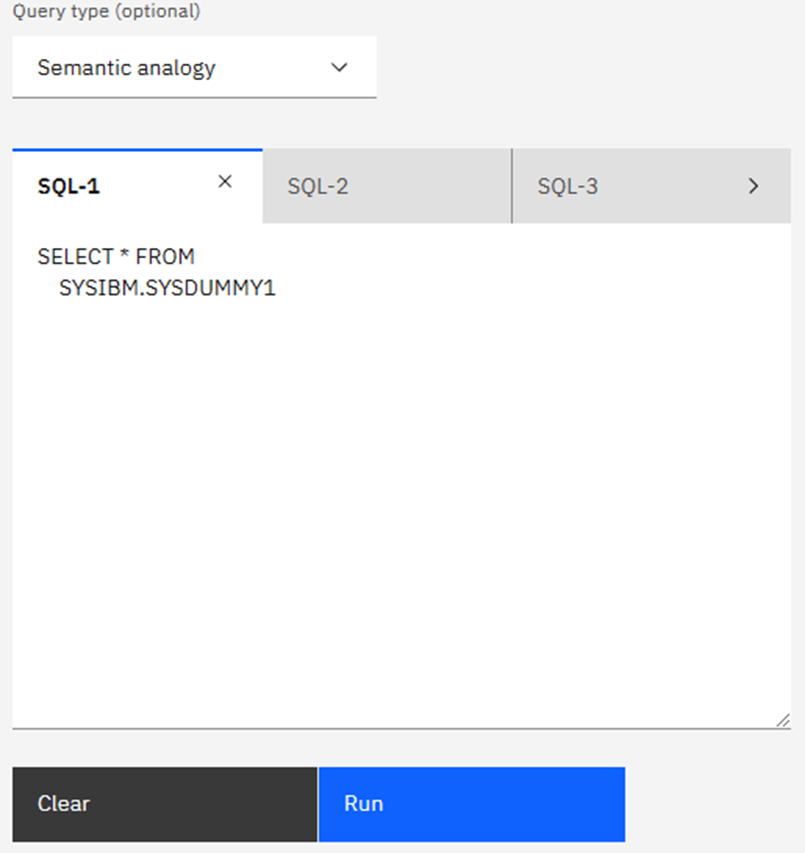
Going back to the List AI Objects window, there are two blue buttons: Add object and Run query. I did not discuss Run Query last month but it gives you a SPUFI-like ability on the PC, tailored to the AI BiFs:
Lets RUN Away!
Clicking on Query type gives a drop-down list of the basic AI BiFs where it then gives you an example SQL (based on the documentation, *not* on any AI Tables you might have done!). Once you type in any query the “run” box turns blue:
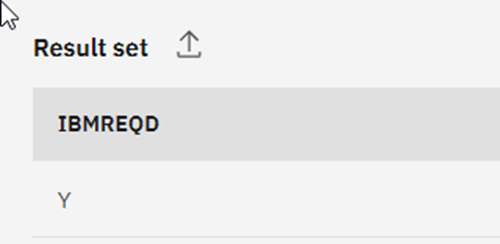
It Works!
Click run and see the results:
Data Review
Once the model is trained, you can then review on the host what it has done. In SPUFI you can find details of what you have done in the pseudo Db2 catalog tables that support Data Insights, (I have removed a ton of rows to make this readable – sort of!):
SELECT * FROM
SYSAIDB.SYSAIOBJECTS ;
---------+---------+---------+---------+---------+---------+---------+---------+-------+-
OBJECT_ID OBJECT_NAME OBJECT_TYPE SCHEMA NAME
---------+---------+---------+---------+---------+---------+---------+---------+-------+-
26 -------------------------------- T IQA061QB IQATW001
-------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+
STATUS CONFIGURATION_ID MODEL_ID CREATED_BY CREATED_DATE
-------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+
Enabled 36 36 SQLDIID 2023-02-24-07.57.42.086932
-------+---------+---------+---------+---------+---------+---------+---------+
LAST_UPDATED_BY LAST_UPDATED_DATE DESCRIPTION
-------+---------+---------+---------+---------+---------+---------+---------+
SQLDIID 2023-03-01-10.43.38.407460 ----------------
SELECT * FROM
SYSAIDB.SYSAICONFIGURATIONS ;
---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+-----
CONFIGURATION_ID NAME OBJECT_ID RETRAIN_INTERVAL KEEP_ROWIDENTIFIER_KEY
---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+-----
36 -------------------------------- 26 ---------------- Y
---+---------+-------
NEGLECT_VALUES
---+---------+-------
---+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+--------
CREATED_BY CREATED_DATE LAST_UPDATED_BY LAST_UPDATED_DATE
---+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+--------
SQLDIID 2023-03-01-09.51.00.994421 SQLDIID 2023-03-01-09.51.00.994461
SELECT * FROM
SYSAIDB.SYSAICOLUMNCONFIG
ORDER BY 1 , 3 , 2 ;
--+---------+---------+---------+---------+---------+---------+---------+---------+---------+
CONFIGURATION_ID COLUMN_NAME COLUMN_AISQL_TYPE COLUMN_PRIORITY NEGLECT_VALUES
--+---------+---------+---------+---------+---------+---------+---------+---------+---------+
36 END_USERID C H
36 PRIM_AUTHOR C H
36 PROGRAM C H
36 REF_TABLE C H
36 REF_TAB_QUAL C H
36 STMT_ORIGIN C H
36 STMT_TEXT C H
36 TRANSACTION C H
36 WORKSTATION C H
36 COPIES_NO I H
.
.
.
36 WLX_TYPE I H
36 WORKSTATION_OLD I H
36 STMT_ID K H
36 CPU_TIME N H
36 ELAPSE_TIME N H
36 EXECUTIONS N H
36 GETP_OPERATIONS N H
36 ROWS_EXAMINED N H
36 ROWS_PROCESSED N H
36 STMT_LENGTH N H
When the column COLUMN_AISQL_TYPE has a value of “I” it means it is ignored by AI processing. Also note that this table SYSAICOLUMNCONFIG gets two extra columns (COLUMN_VECTOR_CARDINALITY and MAX_DATA_VALUE_LEN) once you apply the vector prefetch upgrade APARs:
For IBM Z AI Optimization (zAIO) library and IBM Z AI Embedded (zADE) library in the IBM Z Deep Neural Network (zDNN) stack on z/OS: • Apply OA63950 and OA63952 for z/OS 2.5 (HZAI250). • Apply OA63949 and OA63951 for z/OS 2.4 (HBB77C0).
For OpenBLAS on z/OS: • Apply PH49807 and PH50872 for both z/OS 2.5 and z/OS 2.4 (HTV77C0). • Apply PH50881 for z/OS 2.5 (HLE77D0). • Apply PH50880 for z/OS 2.4 (HLE77C0).
For Db2 13 for z/OS, apply PH51892. Follow the instructions for DDL migration outlined in the ++ HOLD text. By default, the new Db2 subsystem parameter MXAIDTCACH is set to 0, indicating that vector prefetch is disabled. To enable vector prefetch, set MXAIDTCACH to a value between 1 and 512. This parameter is online changeable. See “IBM Db2 13 for z/OS documentation” on MXAIDTCACH.
For SQL Data Insights 1.1.0 UI and model training (HDBDD18), apply PH51052.
Further, the table SYSAIMODELS got a new column MODEL_CODE_LEVEL and an increase in size for the METRIC column to 500K with the above APARs.
SELECT * FROM
SYSAIDB.SYSAIMODELS ;
---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------
MODEL_ID NAME OBJECT_ID CONFIGURATION_ID VECTOR_TABLE_CREATOR
---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------
36 -------------------------------- 26 36 DSNAIDB
+---------+---------+--
VECTOR_TABLE_NAME
+---------+---------+--
AIDB_IQA061QB_IQATW001
+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+
VECTOR_TABLE_STATUS VECTOR_TABLE_DBID VECTOR_TABLE_OBID VECTOR_TABLE_IXDBID VECTOR_TABLE_IXOBID VECTOR_TABLE_VERSION
+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+
A 329 3 329 4 1
-------+---------+---------+---------+---------+---------+---------+---------+-------
METRICS
-------+---------+---------+---------+---------+---------+---------+---------+-------
[{"discriminator":8.59443984950101,"influence":0.9367419701380996,"name":"TRANSACTION",
-------+---------+---------+
INTERPRETABILITY_STRUCT
-------+---------+---------+
-------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+----
CREATED_BY CREATED_DATE LAST_UPDATED_BY LAST_UPDATED_DATE
-------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+----
SQLDIID 2023-03-01-09.51.03.777504 SQLDIID 2023-03-01-10.43.37.796847
---+---------+---------+---------+---------+--
MODEL_ROWID
---+---------+---------+---------+---------+--
2495E518C773B081E09C018000000100000000002213
SELECT * FROM
SYSAIDB.SYSAICOLUMNCENTERS
ORDER BY 1 , 2 , 3 ;
----+---------+---------+---------+---------+---------+---------+
MODEL_ID COLUMN_NAME CLUSTER_MIN LABEL
----+---------+---------+---------+---------+---------+---------+
36 CPU_TIME -0.7200000000000000E+76 EMPTY
36 CPU_TIME +0.0 E+00 c0
36 CPU_TIME +0.2000000000000000E+01 c1
36 CPU_TIME +0.1617671400000000E+08 c9
36 ELAPSE_TIME -0.7200000000000000E+76 EMPTY
36 ELAPSE_TIME +0.0 E+00 c0
36 ELAPSE_TIME +0.2000000000000000E+01 c1
36 ELAPSE_TIME +0.1008466600000000E+08 c9
36 ELAPSE_TIME +0.1074954980000000E+09 c10
SELECT * FROM
SYSAIDB.SYSAITRAININGJOBS ;
---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+--------+-------
TRAINING_JOB_ID OBJECT_ID CONFIGURATION_ID MODEL_ID STATUS PROGRESS RESOURCE
---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+--------+-------
33 26 33 33 F 0
34 26 34 34 F 0
35 26 35 35 C 100
36 26 36 36 C 100
-+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+------
MESSAGES
-+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+------
{"messages":"failed to train model: Something went wrong with the zLoad, please check the SQL DI log for more details.","resumeI
{"messages":"failed to train model: Something went wrong with the zLoad, please check the SQL DI log for more details.","resumeI
{"messages":"model training is completed","sparkSubmitId":"driver-20230224105851-0002"}
{"messages":"model training is completed","sparkSubmitId":"driver-20230301085133-0003"}
-+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+----
START_TIME END_TIME CREATED_BY CREATED_DATE
-+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+----
2023-02-24-08.01.20.737455 2023-02-24-08.51.56.386011 SQLDIID 2023-02-24-08.01.20.737455
2023-02-24-10.52.27.687965 2023-02-24-11.43.22.095144 SQLDIID 2023-02-24-10.52.27.687965
2023-02-24-11.58.20.109571 2023-02-24-12.49.20.660143 SQLDIID 2023-02-24-11.58.20.109571
2023-03-01-09.51.03.777662 2023-03-01-10.43.38.407414 SQLDIID 2023-03-01-09.51.03.777662
---+---------+---------+---------+---------+---------+------
LAST_UPDATED_BY LAST_UPDATED_DATE
---+---------+---------+---------+---------+---------+------
SQLDIID 2023-02-24-08.51.56.386030
SQLDIID 2023-02-24-11.43.22.095164
SQLDIID 2023-02-24-12.49.20.660160
SQLDIID 2023-03-01-10.43.38.407425
KPIs from my Data
Here are a few KPIs from these first test runs:
SELECT COUNT(*) FROM IQA061QB.IQATW001 ;
64390
SELECT COUNT(*) FROM DSNAIDB.AIDB_IQA061QB_IQATW001 ;
49173
SELECT SUBSTR(A.COLUMN_NAME, 1, 12) AS COLUMN_NAME
, SUBSTR(A.VALUE , 1, 12) AS VALUE
, A.VECTOR
FROM DSNAIDB.AIDB_IQA061QB_IQATW001 A
ORDER BY 1 , 2 ;
---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+--
COLUMN_NAME VALUE VECTOR
---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+--
CPU_TIME c0 3E594822BC9D2C7A3CD4F61DBD37E5033D34B314BD4CF8E3BD4B4D47BCB6CE293D1DBA1A3D858FDF3DC4DF08BD9E77753CCED43F
CPU_TIME c1 3D9214383CFE4C90BDB3DFE4BBE407563BBA69553DB48FEFBCF39451BC6BABF0BDA31BDFBDB52F883C30B992BC8D71AF3D9E54FF
ELAPSE_TIME c0 3E55B744BCCC5CED3D129B14BC9E553C3C9B121EBD8949C0BD4F838DBD1582A33D36D6363DA1F72F3DBCB033BDAFB88F3D4DE348
ELAPSE_TIME c1 3DE390AC3D2DCC98BD2DF437BC5B7F713D766D103BD1AC10BB48E2C43B9FA9E6BD80D5D7BDC40AFE3CE586C9BCACADE93DFE2745
END_USERID BOXWEL2 3D505075BD80E40F3D3AAB60BBA463F6BBCC51C43D92B118BD044D20BD8C6B3B3CC315133BBB087A3DC1D5923DC4EB763D039C8B
END_USERID BOXWEL3 3D2FB919BC5013E3BD6652DDBD4654DA3DA4AC83BA70024FBD7FAFD0BCF16670BB2CCB4B3DBE32E93DFE13383CB052283C82FD46
As I mentioned last month the vector tables are very “special”!
What now?
So now we have analyzed a bunch of SQL WorkLoadExpert data from our own labs. What can we do?
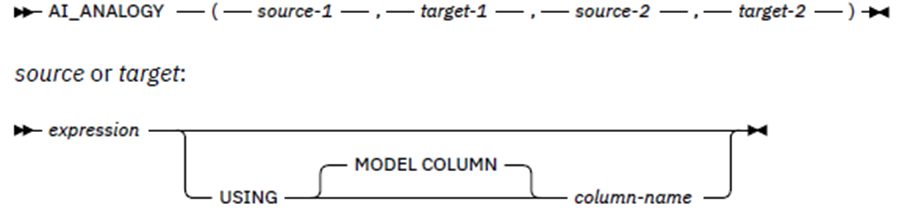
First up, I wish to see what user KKKKKKK does with dynamic SQL that is “similar” to what I do with table IQATW001 but I am only interested in those SQLs where the AI thinks it is more than 0.5 (so very analogous):
SELECT AI_ANALOGY('BOXWEL3' USING MODEL COLUMN PRIM_AUTHOR,
'IQATW001' USING MODEL COLUMN REF_TABLE ,
'KKKKKKK' USING MODEL COLUMN PRIM_AUTHOR,
REF_TABLE ) AS AI_VALUE
,A.WLX_TIMESTAMP
,A.STMT_ID
,A.STMT_TIMESTAMP
,SUBSTR(A.PRIM_AUTHOR , 1 , 8 ) AS PRIM_AUTHOR
,SUBSTR(A.PROGRAM , 1 , 8 ) AS PROGRAM
,SUBSTR(A.REF_TABLE , 1 , 18) AS REF_TABLE
,A.EXECUTIONS
,A.GETP_OPERATIONS
,A.ELAPSE_TIME
,A.CPU_TIME
,A.STMT_TEXT
FROM IQA061QB.IQATW001 A
WHERE A.PRIM_AUTHOR = 'KKKKKKK'
AND AI_ANALOGY('BOXWEL3' USING MODEL COLUMN PRIM_AUTHOR,
'IQATW001' USING MODEL COLUMN REF_TABLE ,
'KKKKKKK' USING MODEL COLUMN PRIM_AUTHOR,
REF_TABLE )
> 0.5
ORDER BY 1 DESC -- SHOW BEST FIRST
--ORDER BY 1 -- SHOW WORST FIRST
FETCH FIRST 2000 ROWS ONLY ;
All interesting stuff! I use dynamic SQL to INSERT into the table a lot, and it has determined that use of dynamic SQL with tables R510T002 and IQATA001 is analogous. In fact, it is! The SQLs were all INSERT, DELETE and UPDATE… Clever ol’ AI!
Dynamic Duo?
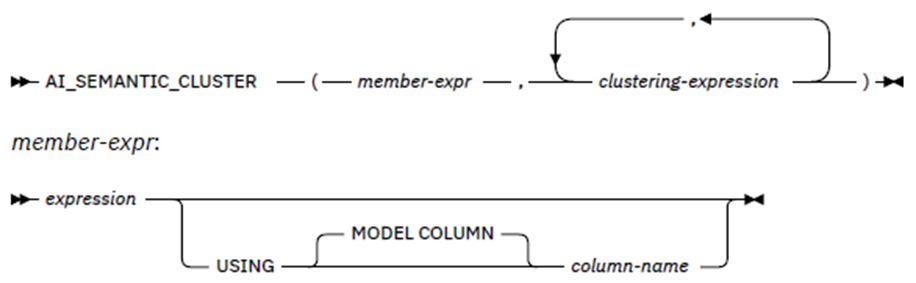
Now I wish to see which programs process dynamic SQL like the IBM DSNTIAD and DSNTIAP programs:
SELECT AI_SEMANTIC_CLUSTER( PROGRAM,
'DSNTIAD',
'DSNTIAP') AS AI_VALUE
,A.WLX_TIMESTAMP
,A.STMT_ID
,A.STMT_TIMESTAMP
,SUBSTR(A.PROGRAM , 1 , 8) AS PROGRAM
,A.EXECUTIONS
,A.GETP_OPERATIONS
,A.ELAPSE_TIME
,A.CPU_TIME
,A.STMT_TEXT
FROM IQA061QB.IQATW001 A
WHERE A.PROGRAM NOT IN ('DSNTIAD', 'DSNTIAP')
AND A.STMT_ORIGIN = 'D'
ORDER BY 1 DESC -- SHOW BEST FIRST
--ORDER BY 1 -- SHOW WORST FIRST
FETCH FIRST 10 ROWS ONLY ;
Again, very nice – it spotted all of the RealTime DBAExpert Dynamic SQL access programs in use…
Undynamic Duo?
Ok, now the opposite of that query, show me the SQLs that are like them but not them!
SELECT AI_SEMANTIC_CLUSTER( PROGRAM,
'DSNTIAD',
'IQADBACP',
'SEDBTIAA') AS AI_VALUE
,A.WLX_TIMESTAMP
,A.STMT_ID
,A.STMT_TIMESTAMP
,SUBSTR(A.PRIM_AUTHOR , 1 , 8) AS PRIM_AUTHOR
,SUBSTR(A.PROGRAM , 1 , 8) AS PROGRAM
,SUBSTR(A.REF_TABLE , 1 , 18) AS REF_TABLE
,A.EXECUTIONS
,A.GETP_OPERATIONS
,A.ELAPSE_TIME
,A.CPU_TIME
,A.STMT_TEXT
FROM IQA061QB.IQATW001 A
WHERE A.PROGRAM NOT IN ('DSNTIAD', 'IQADBACP' ,'SEDBTIAA')
--AND A.STMT_ORIGIN = 'D'
--ORDER BY 1 DESC -- SHOW BEST FIRST
ORDER BY 1 -- SHOW WORST FIRST
FETCH FIRST 10 ROWS ONLY ;
Aha! It found a little assembler program that fires off SQL like the top three!
The Apple doesn’t Fall far from the Tree
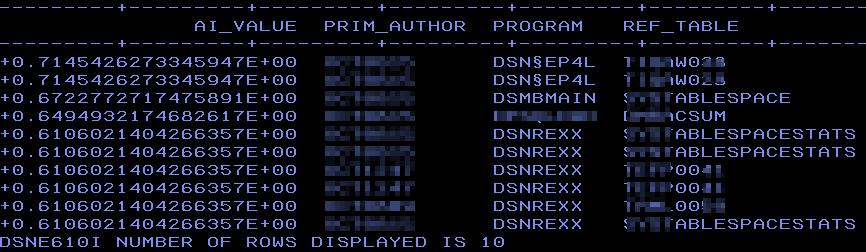
Finally, I want to see which programs behave like IQADBACP (our main dynamic SQL driver program):
SELECT AI_SIMILARITY( PROGRAM,
'IQADBACP') AS AI_VALUE
,A.WLX_TIMESTAMP
,A.STMT_ID
,A.STMT_TIMESTAMP
,SUBSTR(A.PROGRAM , 1 , 8) AS PROGRAM
,A.EXECUTIONS
,A.GETP_OPERATIONS
,A.ELAPSE_TIME
,A.CPU_TIME
,A.STMT_TEXT
FROM IQA061QB.IQATW001 A
WHERE NOT A.PROGRAM = 'IQADBACP'
AND A.STMT_ORIGIN = 'D'
ORDER BY 1 DESC -- SHOW BEST FIRST
--ORDER BY 1 -- SHOW WORST FIRST
FETCH FIRST 10 ROWS ONLY;
And the output:
---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---
AI_VALUE WLX_TIMESTAMP STMT_ID STMT_TIMESTAMP PROGRAM
---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---
+0.4575602412223816E+00 2023-02-02-10.45.26.535375 7 2023-01-17-16.50.54.118774 O2DB6X
+0.4575602412223816E+00 2023-01-06-05.27.28.779825 7 2023-01-17-16.50.54.118774 O2DB6X
+0.4400676488876343E+00 2023-01-06-05.27.28.779825 220 2023-01-20-10.11.14.618038 DSMDSLC
+0.4400676488876343E+00 2023-01-06-05.27.28.779825 222 2023-01-20-10.11.38.136712 DSMDSLC
+0.4400676488876343E+00 2023-01-06-05.27.28.779825 221 2023-01-20-10.11.21.993833 DSMDSLC
+0.4400676488876343E+00 2023-01-06-05.27.28.779825 252 2023-01-20-10.55.07.078652 DSMDSLC
+0.4400676488876343E+00 2023-01-06-05.27.28.779825 251 2023-01-20-10.54.37.901247 DSMDSLC
+0.4400676488876343E+00 2023-01-06-05.27.28.779825 233 2023-01-20-10.47.23.961076 DSMDSLC
+0.4400676488876343E+00 2023-01-06-05.27.28.779825 232 2023-01-20-10.46.59.756430 DSMDSLC
+0.4400676488876343E+00 2023-01-06-05.27.28.779825 224 2023-01-20-10.33.42.609175 DSMDSLC
+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+-
EXECUTIONS GETP_OPERATIONS ELAPSE_TIME CPU_TIME STMT_TEXT
+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+-
0 0 0 0 SELECT COALESCE(COALESCE(A.DBNAME,B.DBNAME),C
2 7 27753 1236 SELECT COALESCE(COALESCE(A.DBNAME,B.DBNAME),C
2 1387 57974 14900 SELECT CASE WHEN B.VCATNAME < ' ' THEN '00000
6 4170 68943 53330 SELECT CASE WHEN B.VCATNAME < ' ' THEN '00000
6 4596 286233 99773 SELECT CASE WHEN B.VCATNAME < ' ' THEN '00000
1 851 55367 42542 SELECT CASE WHEN B.VCATNAME < ' ' THEN '00000
1 298 122961 24848 SELECT CASE WHEN B.VCATNAME < ' ' THEN '00000
2 1260 68272 48952 SELECT CASE WHEN B.VCATNAME < ' ' THEN '00000
1 192 3395 2508 SELECT CASE WHEN B.VCATNAME < ' ' THEN '00000
3 810 43520 23771 SELECT CASE WHEN B.VCATNAME < ' ' THEN '00000
Again, it found all of the correct programs.
Quibble Time!
I did find some small problems…
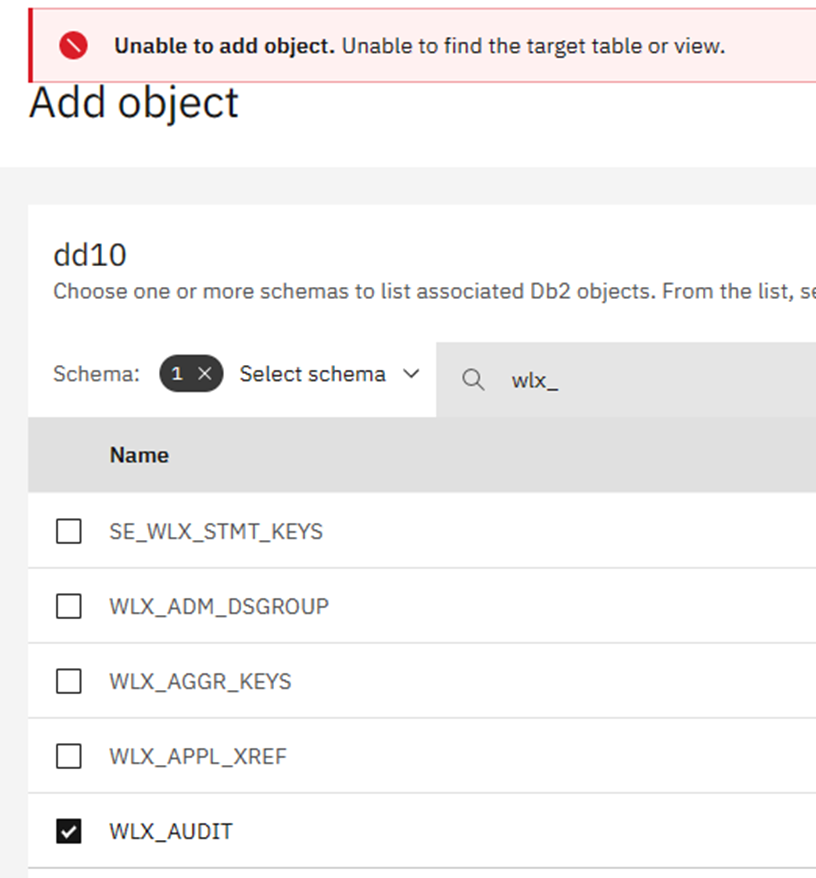
I use ALIASes a lot and they appear in the drop-down selection box when in “Add object”, but if you choose one as an AI Object:
This then leads on to the second quibble… The red windowed error messages stay there until you click them away… This can lead you to believe that a problem exists when in reality everything is groovy!
I also found out that the spinning wheel completes if you wait for Spark and LOAD and then go back and forward on the panel.
Finally, the way you move around the product is a bit odd… sometimes you use the browser back function, sometimes you click on a “Back” button, sometimes you click on a bread crumb, sometimes there are multiple options hidden under triple vertical dots which change depending on where you are in the process.
I am sure these little UI bugs will all get ironed out very quickly!
End of Quibbles.
First Baby Steps Taken!
This little trip into the AI world is really just the tip of the iceberg. I will be doing many more AI queries over the coming months, and I hope to show all my results, either here or in another one of my Newsletters and/or at the German GUIDE in April 2023 and, hopefully, at the IDUG 2023 as well.
Any questions about AI, do not fear to ask, and when not me then ChatGPT!
Ok, ok, I am a little bit of a geek… But in my defense at least I have started kicking around with Artificial Intelligence and not just ChatGPT! This month, I wish to dip my toes into the icy, cold waters of AI and show you what you can do in Db2 13 right out-of-the-box !
What’s in a BiF?
Db2 13 FL500 brings three new Scalar BIFs. These are the SQL Data Insights functions. They come supplied with Db2 13 but you do have to install a bunch of stuff to actually get them working (so not really out-of-the-box, but close!)
Five Easy Steps?
First, you need to make sure you have all the prereqs in place. These are basically a couple of APARs for the IBM Z Deep Neural Network Library (zDNN), the z/OS Supervisor, IBM OpenBLAS, z/OS OpenSSH and IBM 64-bit SDK for z/OS Java. zDNN and OpenBLAS come with z/OS 2.4/2.5, but without the required APARs the libraries may be empty.
SQL Data Insights (SQL DI) is a kind of no-charge add-on to Db2 13, so you need to order and install it separately (FMID HDBDD18).
Then you need to install and customize SQL DI, starting with the definition of a (technical) user along with its appropriate authorization (Configuring setup user ID for SQL Data Insights). They’re asking for 100 GB of storage for the zFS home directory, but I think you’ll only need that when you start to run AI model training on vast amounts of data. For my first tiny steps into the world of Db2 AI it worked with a tenth of that without any problems. It may well change with my soon upcoming tests! The requirements listed for CPU and system memory aren’t much smaller and I’m experiencing a very measurable CPU consumption whenever the model training on an object starts.
RACF for Advanced Users!
The next step (Configuring user authentication for SQL Data Insights) is very likely a task for your RACF colleague, unless you have RACF SPECIAL authority (Who on earth *ever* has SPECIAL these days … any auditor would throw a right royal wobbly there!) or sufficient authority as described in RACDCERT command. RACDCERT manages RACF digital certificates and SQL DI needs that to allow secure (https) connections to the user interface, coming as an easy-to-use web application.
While You are Waiting, Sir…
While your RACF colleague is getting the (technical) user and the certificate in place, you can sneak into Db2’s SDSNSAMP lib to customize and execute DSNTIJAI. This guy creates the required database and pseudo-catalog tables as described in Configuring Db2 for SQL Data Insights. There are also GRANTs in the sample job, but I had to add another one for procedure DSNWLM_UTILS, since SQL DI uses that for LOAD.
And We are Finished!
Finally, you must do the SMP/E installation of SQL DI, followed by executing the installation script in the USS environment as described in Installing and configuring SQL Data Insights. USS scripts seem to be (along with certificates) the fun part of installing products these days. Carefully plan, and stick with, the values that you enter during the interactive installation of the sqldi.sh script. If you re-run the installation, for example, and decide for another SQLDI_HOME, your .profile will have a # Generated by SQL Data Insights installation script section that will not be updated. The script also starts SQL DI and SPARK (needed and installed by SQL DI). However, there seem to be some very low internal timeout values set for verifying the successful start – at least in my environment. The script complained that start failed, but it was all up and running fine. After you verified the successful installation as described at Verifying the installation and configuration of SQL Data Insights, you can start having fun with SQL DI. I, however, decided to additionally go for the optional step Creating a started task for the SQL Data Insights application. If you intend to use SQL DI more than once, and maybe have your colleagues also work with it, I think this piece is a must. Be aware that there are a couple of adjustments to make it work:
The sample STDENV, as well as the samples that are in the SQLDAPPS STC sample job don’t have all the definitions of the .profile sample, which I added manually.
The _CEE_RUNOPTS=“…“ sample didn’t work for me and I had to remove the quotation marks to make it look like _CEE_RUNOPTS=FILETAG(AUTOCVT,AUTOTAG) POSIX(ON)
Starting/Stopping SQLDAPPS using SQLDAPPS sample job triggers sqldi.sh with the start/stop option. This is accomplished by two members in the PDS specified by the STDPARM DD card. The STOP is issued by command /s SQLDAPPS,OPTION=’SQLDSTOP‘ (for what ever reason not by STOP SQLDAPPS) and correctly refers to member SQLDSTOP. The START is issued by command /s SQLDAPPS,OPTION=’STRT‘. However, the member is actually called SQLDSTRT, so it either requires to change the STCs sample job default option to SQLDSTRT, or the member to be renamed as STRT.
There is also an optional step to create an STC for the SPARK cluster in the docu (Creating started tasks for the Spark cluster). Short story: Skip it, because SQL DI will start the SPARK cluster (master and worker) automatically anyways.
Once installed and ok, you can then kick off the web interface. The first page is a login panel of course:
Time to get Connected
Here you can see that I have already defined my little test Db2 13 to the system:
If you click on “Add connection” you get a pop-up to define how to get to another Db2 using a certificate or a userid and password, very similar to setting up a Data Studio connection. Click on the three dots and you get a drop-down box:
Here you can disconnect, Edit (Which shows you the same window as “add connection”), List AI objects or Delete.
Starting to Feel Intelligent!
Choosing List AI objects you see what I have created:
I’m Sorry, Dave, I’m Afraid I can’t do That.
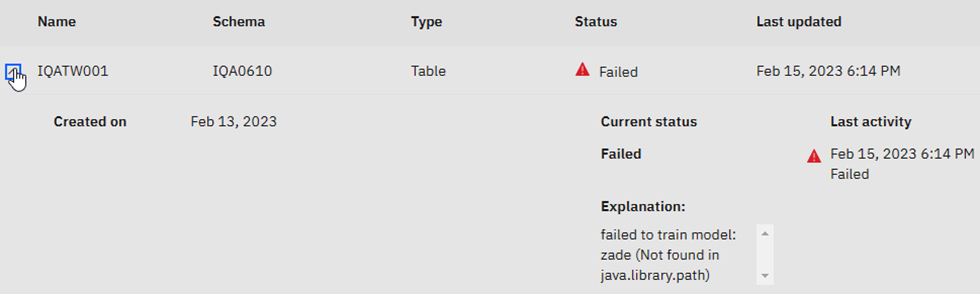
Sadly, it failed – Click on the downward arrow expands the view:
When I first heard “zade” I thought of Sade – “Smooth Operator” for some reason…The explanation is actually a hint that something is wrong with the JAVA definitions. It could be a classpath problem or a version problem. This is in work as I write this!
Can you hear me, HAL?
Now the Enable AI query I will cover later, first Analyze data takes you to the next window:
Just the Facts, Ma’am
Click on Data statistics for a different view:
Column influence:
Has no function yet as the training failed…
An Overview is Good
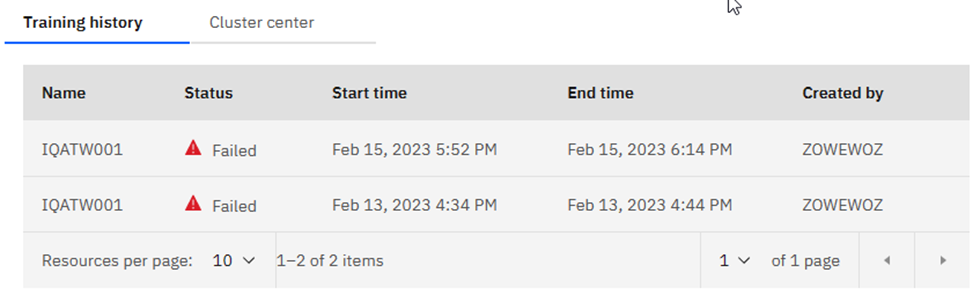
Selecting View model shows you the history of this model:
Naturally, Cluster center shows this:
Is There an Export Limit?
Export Columns creates a JSON file:
Which then looks like:
Pretty horrible if you ask me!
Skipping back to HAL
Going back to the List AI Objects window, there are two blue buttons: Add object and Run query.
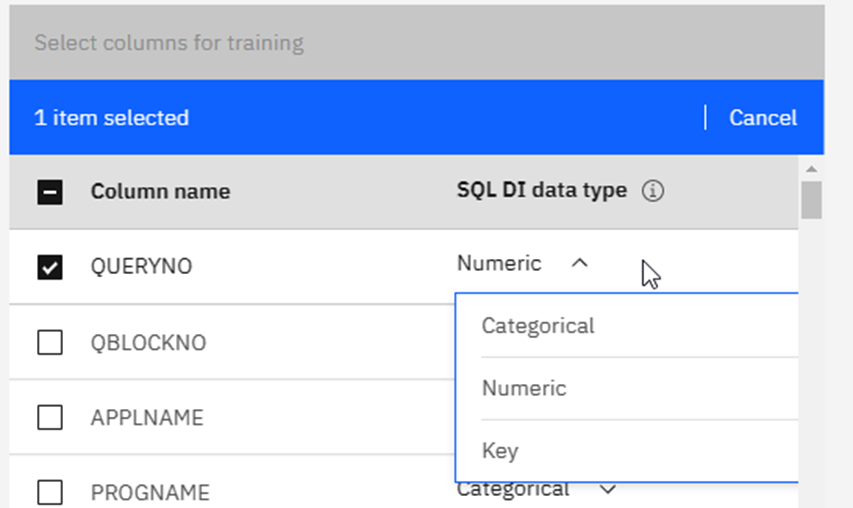
Add Object is how I added my first table, it is basically a catalog browser where you can pick the table of choice and, once selected, the greyed-out boxes at the bottom turn blue and you may click on Add object or Enable AI query. Having added a table you then do indeed click on Enable AI query to decide which columns have which DI data type. This is the most critical moment in the whole process!
When you select a column, you can decide on a data type:
Categorical, Numeric or Key. Once you have decided this for all of the columns click on Next:
Here you get the Filter chance:
Last Chance to Turn Back…
Now you have the choice to filter again or just click on Enable:
This now kicks off an Apache Spark process in the background that sucks all of the CPU and memory from your system for a while and builds a new vector table in the background. The vector table actually contains the model data to be used by the new BiFs.
In SPUFI you can find your vector table:
It is “AIDB_” concatenated with your table creator an underscore and then table name.
There are only three columns and, naturally, due to the failure of the model training, my vector table is empty… The COLUMN_NAME here is the column name that is referred to from now on in this blog.
Round up the Usual Suspects!
The vector data tables are very, very special… you cannot simply copy them between systems like normal data and you must make sure they stay in step with their partner “real data” tables – and here I specifically mean image copies!
Once a model is trained, you can use the new BiFs. The documentation is a bit sparse and it does not explicitly say you can use numeric data types, but it also does not explicitly say you cannot! In fact, the list of “cannot use types” are always the same:
BINARY, VARBINARY, CLOB, BLOB, DBCLOB, XML or ROWID.
Maximum length of the used column is 1868 Bytes.
Where’s the Beef?
Here are the currently available AI BiFs with examples taken from the docu.
This is the human language equivalent of Source-1 is to Target-1 as Source-2 is to Target-2.
The Column Name is the identifier which points to the model and column name to be used for this AI function (COLUMN_NAME in the vector table) and, if not given, then the expression determines the column name or it is just the actual table column name. The model specified must, obviously, be the same for both Sources and the same for both Targets.
Here’s an example showing the syntax:
The customer with ID ‘1066_JKSGK’ has churned. Given the relationship of that customer to ‘YES’ in the churn column, find customers with the same relationship to ‘NO’ in the churn column, in other words, customers unlikely to churn.
SELECT AI_ANALOGY('YES' USING MODEL COLUMN CHURN,
'1066_JKSGK' USING MODEL COLUMN CUSTOMERID,
'NO' USING MODEL COLUMN CHURN,
CUSTOMERID),
CHURN.*
FROM CHURN
ORDER BY 1 DESC
FETCH FIRST 5 ROWS ONLY ;
The result is a double precision floating point number. The larger the positive value the better the analogy and a value of -1 is a poor analogy. Caution must be used as the result can also be NULL if any of the args are NULL.
This returns a clustering score for the member-expr value among the cluster of values defined in the, up to three times repeated, clustering expression list. Like AI_ANALOGY the model to be used is either the member-expr column name or the explicit column name.
Here’s an example showing the syntax:
Customers with IDs ‚0280_XJGEX‘, ‚6467_CHFZW‘ and ‚0093_XWZFY‘ have all churned. If we form a semantic cluster of those three customers, find the top 5 customers that would belong in that cluster.
SELECT AI_SEMANTIC_CLUSTER(CUSTOMERID,
'0280_XJGEX', '6467_CHFZW', '0093_XWZFY'),
CHURN.*
FROM CHURN
ORDER BY 1 DESC
FETCH FIRST 5 ROWS ONLY ;
The result is a double precision floating point number between -1.0 and +1.0 that is the semantic clustering score. A larger positive number indicates a better clustering among the list of clusters. Caution must be used, as the result can also be NULL if any of the arguments are NULL or were not seen during training.
This returns a similarity score for the two expressions. Like AI_ANALOGY, the model to be used is either the expression column or the explicit column name.
Here are two examples showing the syntax:
Find the top five customers by ID most similar to the customer with ID ‚3668-QPYBK‘.
SELECT AI_SIMILARITY(CUSTOMERID,
'3668-QPYBK'),
CHURN.*
FROM CHURN
ORDER BY 1 DESC
FETCH FIRST 5 ROWS ONLY;
Find the top three payment methods most similar to ‚YES‘ in the CHURN column.
SELECT DISTINCT AI_SIMILARITY(PAYMENTMETHOD,
'YES' USING MODEL COLUMN CHURN),
PAYMENTMETHOD
FROM CHURN
ORDER BY 1 DESC
FETCH FIRST 3 ROWS ONLY ;
The result is a double-precision floating point number (FLOAT) that is the similarity score between -1.0 and 1.0, where -1.0 means that the values are least similar, and 1.0 means that they are most similar.
With this BiF you can get NULL returned if the columns of interest are numeric types but the value is outside of the range of FLOAT. Further, NULL is returned if any argument is NULL and also if the value was not available during training and the column is not numeric.
Follow the Money!
This is all you get out-of-the-box in Db2 13 – The real question is, „For which business use cases does it make sense to use these BiFs?“ That is naturally a very hard question and next month I hope to bring you real life AI examples from my test data (as long as I can get my Models trained!)
This year (well, strictly speaking last year…) IDUG EMEA changed from running Monday to Wednesday to being from Sunday to Tuesday. This caught a few people out with travel plans, etc. but all in all it was ok as a „once off“. It was also held after a two-year COVID delay in the beautiful city of Edinburgh, where it normally rains a day longer than your stay but I only had rain on one day! Mind you, that did coincide with tornado style, umbrella-shredding winds that made going anywhere more like a swim, but what can I say? The Haggis was excellent, the Whisky’s were simply gorgeous and all the people were incredibly friendly. Not just the visitors to the IDUG either!
All a bit late, I know, but I have been terribly busy doing other „real“ work… So, with no further ado, off we go through the Db2 for z/OS IDUG presentations!
Please remember, to use the links below you *must* have been at the IDUG 2022 EMEA and/or you are an IDUG Premium member and remember your IDUG Userid and password!
Starting with Track A: Db2 for z/OS I
A01 Db2 13 for z/OS and More! from Haakon Roberts and Steven Brazil gave a great intro to Db2 13, the history behind it and the AI-driving force within. Finishing off with Db2 13 highlights. Our very own Andre Kuerten rated Haakon as the best overall presenter by the way.
A02 Db2 13 for z/OS Performance Overview, from Akiko Hoshikawa did what it said. A deep dive through all the performance stuff, including updates on Db2 12 and synergy with z Hardware.
A03 Db2 13 for z/OS Migration, Function Levels and Continuous Delivery from „The Dynamic Duo“ of Anthony Ciabattoni and John Lyle was a review of all the Db2 12 functions and then an update on how to do the migration to Db2 13 – Which should be faster and less troublesome than to Db2 12.
A04 Now You See It, Unveil New Insights Through SQL Data Insights from Akiko Hoshikawa was the first of many presentations to go into depth all about AI, as various bits of AI are now available out-of-the box with Db2 13. Still a few things to do of course… 50GB of USS data for the SPARK for example … but at least no need for machine learning (ML). At the very end was also a glimpse into the future and the next three BiFs coming our way soon!
A05 Getting Ready for Db2 13 from John Lyle was another review of continuous delivery and how to get to Db2 12 FL510, which is the migration point for Db2 13 FL100.
A06 Db2 for z/OS Utilities – What’s New? from Haakon Roberts was the usual excellent presentation and run down of all the latest new stuff on the utilities front and also any Db2 13 stuff as well. As always well worth a read!
A09 Db2 Z Network Encryption: Overview and How to Identify End-Users Using Open Port from Brian Laube was a fascinating presentation all about fully understanding this problem as it is, or will be, a problem in all shops at some point in the future! The presentation also included an example NETSTAT from TSO to help you find the „bad guys“ before you switch to 100% SECPORT usage. At the end was a very nice list of AHA requests/ideas/wishes which I would also appreciate if some people voted for!
A14 Express Yourself from Marcus Davage was an excellent romp through the horrors of REGEX and ended up with a quick way to solve WORDLE…all a bit dubious if you ask me! What with the recursive SQL from Michael Tiefenbacher and Henrik Loeser solving Sudoku and now Marcus solving Wordle what is left for our brains to do??? The link to github for Sudoku is:
https://github.com/data-henrik/sql-recursion
Thanks to Michael and especially to Henrik for the link.
A15 A Row’s Life from Marcus Davage. This is what a row goes through in its daily life – fascinating! A deep technical dive into the data definition of pages etc etc.
B03 Db2 13 for z/OS Application Management Enhancements from Tammie Dang. The highlights for applications were reviewed, highlighting timeouts and deadlocks and the way that SYSTEM PROFILES can easily help you get what you want without massive REBINDs.
B05 Ready Player One for Db2 13! from Emil Kotrc. This was another recap of Db2 13 migration, CD, Db2 12 FL501 to FL510 but also with deprecated functions and incompatible changes.
B06 Getting RID of RID Pool RIDdles from Adrian Collett and Bart Steegmans was an entertaining sprint through What is an RID? and When do I have a real RID problem?
B10 Db2 for z/OS Data Sharing: Configurations and Common Issues from Mark Rader. Was a very interesting presentation about exactly how data sharing hangs together and the various ways you can break it or make it better. A Must Read if you have, or are planning on, going to a data sharing system! His anecdote about a forklift truck crashing through the back wall of the data center brought home that „disasters“ are just waiting to happen…
B11 Get Cozy with Traces in Db2 for z/OS from Denis Tronin was a great intro into the usage of Traces for Db2 for z/OS. Included was also an update of which traces have been changed or introduced for the new Db2 12 and 13 features.
B12 Partitioning Advances: PBR and PBR RPN from Frank Rhodes. This gave an excellent review of the history of tablespaces in Db2. Then the new variant PBR RPN was introduced, and how to get there.
B13 Managing APPLCOMPAT for DRDA Application from Gareth Copplestone-Jones. Another review of CD and APPLCOMPAT but this time looking at NULLID packages and the special problems they give you!
B14 Afraid of Recovery? Redirect Your Fears! from Alex Lehmann. This showed the new redirected recovery feature with some background info and a summary about why it is so useful!
B16 DB2 z/OS Recovery and Restart from Thomas Baumann. This is a *one* day seminar… The IDUG live talk was just the first hour (first 34 slides!) and if you ever wish to consider doing RECOVER – Read it all!
B17 Security and Compliance with Db2 13 for z/OS from Gayathiri Chandran. Was all about the IBM Compliance Center and a list of all Audit relevant info in Db2 (Encryption, Audit policies etc.)
Now off to Track E AppDev & Analytics I:
E01 When Microseconds Matter from Thomas Baumann. This was all about tuning a highly tuned system. Where, even if you have 50 microsecond CPU SQL times, you can squeeze even more out of the Lemon! Included are complete SQLs for examining your DSC for tuning candidates that „stayed below the Radar“ before.
E04 Db2 for z/OS Locking for Application Developers from Gareth Copplestone-Jones. All about locking from the developer’s POV. Contains Lock Size recommendations and descriptions of Locking, and Cursors. A very good read!
E07 Beginners guide to Ansible on z/OS from Sreenivas Javvaji started with the pre-reqs like Ubuntu and then adding Ansible and installing the IBM z/OS Core Collection finishing off with yaml.
E09 Access Paths Meet Coding from Andy Green. Contains a DBA view of how application developers let access paths „slide“ over time until incidents start to happen, and how to correct this by putting back „optimization“ into the development process. Extremely useful presentation for Application Developers and SQL coders!
E10 SQL Injection and Db2 – Pathology and Prevention from Petr Plavjaník. A cross platform presentation all about SQL injection and how it can bite you… A very important take away is that it is not „just“ an LUW or distributed problem. Dynamic SQL in COBOL can just as easily be injected…
E13 How Can Python Help You with Db2? From Markéta Mužíková and Petr Plavjaník. Everything you ever wondered about Python but were afraid to ask! Included an installation list explaining some of the more weird environmental variables of the pyenv.sh
E14 Use Profiles to Monitor and Control Db2 Application Context from Maryela Weihrauch. This was all about one of the, in my personal opinion, most underused features of Db2 on z/OS. They have been around for years and they enable so much e.g. Global Variables, driver upgrades, RELEASE(DEALLOCATE) / RELEASE(COMMIT) etc etc
E15 -805 Explained from Emil Kotrc. This explained the whole background of program preparation Precompile, Compile, Link and BIND. Which consistency token goes where and when is it validated?
F03 Is it worth to migrate CICS cobol app to Windows .net ? from Mateusz Książek. Naturally I am a little bit biased here, as I would always say „NO!“. However Mateusz goes on to explain the difficulty of monitoring and comparing the results. It was a bit like apples and oranges after all and he ended on a Pros and Cons slide where you must decide …
F04 COBOL abound from Eric Weyler. This was all about the remarkable life of COBOL and how it is *still* nailed to its perch! There are „new“ forms like gnuCOBOL and new front ends like VS Code and of course Zowe and Web GUIs with z/OSMF.
F07 War of the Worlds – Monolith vs Microservices from Bjarne Nelson. This session highlighted the intrinsic difficulties of going to microservices (Rest et al) in comparison to the „normal“ DBMS ACID style. Finishing with „When to use microservices and when not to!“
F08 SYSCOPY: You cannot live without it! from Ramon Menendez. Detailed everything about this very important member of the Db2 Catalog. It also covered the new things in Db2 12 and 13 as well as a quick look at how SYSIBM.SYSUTILITIES interacts with it.
F09 Playing (with) FETCH from Chris Crone. This was an informative session all about FETCH where even I learnt something … shock, horror!
F17 Explain explained from Julia Carter. This was an introduction in how to use and understand the EXPLAIN statement and its output to help in correcting badly-running SQL.
Finally Track G Daily Special (Sounds like a restaurant…) :
G03 Do I Really Need to Worry about my Commit Frequency? An Introduction to Db2 Logging from Andrew Badgley. Explained the BSDS, the Active and Archive logs and how they all interact with UOW. A recommendation here during Q&A was to COMMIT about every two seconds, and one war story was of a site that had an eight hour batch run which was then deemed to have gone rogue and was duly cancelled… It started rolling back and took a while… Db2 was then shut down – It didn’t of course… IRLM was then cancelled, Db2 came crashing down. Db2 was restarted… Hours passed as it *still* did its ROLLBACK, they cancelled it again… Then restarted and then waited hours for it to actually (re)start properly…
G17 Esoteric functions in Db2 for z/OS from Roy Boxwell. Naturally the best presentation of the EMEA *cough, cough* Could be a little bit biased here… If you wanted to know about weird stuff in Db2 for z/OS then this was your starting point. Any questions drop me a line!!!
My very own Oscar
I was also very proud, and happy, to be awarded an IBM Community Award as a „Newbie IBM Champion“ for 2022! It was at the same time as John Campbell got his for lifetime achievement and was doubly good as I first met John waaaay back in the 1980’s at Westland Helicopters PLC with DB2 1.3 on MVS/XA – Those were the days!
Please drop me a line if you think I missed anything, or got something horribly wrong. I would love to hear from you!
Hi all! Welcome to the end-of-year goody that we traditionally hand out. This year is a relaunch of the Migration HealthCheck that we first did over two years ago. I’ve also provided some news about Db2 13 UTS PBR RPN spaces that might be of interest to you!
DB2 12 UTS PBR RPN
You might well know that this was my single favorite feature of Db2 12. What I did not really appreciate, until now, was the fact that getting these very big partitions can come with a major price!
WHAT IS THE PROBLEM?
If you have a Data Sharing system (Who does not these days?) and you happen to use LOCKSIZE ROW on your UTS PBR RPN then you should take a good look at your performance monitor data. If you see a high number of P-Locks, and the number of false contentions is greater than your IRLM–SUSPENDS, then BINGO!
THE FIX IS?
Documented in the red book „Db2 13 Performance Topics“, Chapter 5 Data Sharing, 5.1 „Partition-by-range table space relative page numbering enhancements“ is the information above, and a lot more. The crux of the matter is a new Hash Algorithm, and to get to it you must simply REORG any UTS PBR RPN spaces that were created prior to Db2 13 FL500.
HERE IS SOME SQL
Here is some SQL to list out any and all of your UTS PBR RPN table partitions that were created prior to Db2 13 FL500 and have not yet been REORGed or LOAD REPLACED.
First check that you are actually *at* Db2 13 R1 FL500!
SELECT LU.EFFECTIVE_TIME FROM SYSIBM.SYSLEVELUPDATES LU WHERE 1 = 1 AND LU.FUNCTION_LVL = 'V13R1M500' AND LU.OPERATION_TYPE = 'F' WITH UR FOR FETCH ONLY ;
This simply returns the time when the FL500 was „activated“ in your Db2 13 system. If it returns no rows then you cannot do anything…
THE USUAL SUSPECTS…
Then we get the Partitions of interest:
SELECT SUBSTR(TP.DBNAME , 1 , 8) AS DBNAME ,SUBSTR(TP.TSNAME , 1 , 8) AS TSNAME ,TP.PARTITION ,TP.CREATEDTS ,TP.REORG_LR_TS FROM SYSIBM.SYSTABLESPACE TS ,SYSIBM.SYSTABLEPART TP WHERE 1 = 1 AND TS.DBNAME = TP.DBNAME AND TS.NAME = TP.TSNAME AND TS.TYPE = 'R' -- UTS PBR ONLY AND TS.LOCKRULE = 'R' -- ROW LEVEL LOCKING ONLY AND TP.PAGENUM = 'R' -- UTS PBR RPN ONLY AND TP.CREATEDTS < (SELECT LU.EFFECTIVE_TIME FROM SYSIBM.SYSLEVELUPDATES LU WHERE 1 = 1 AND LU.FUNCTION_LVL = 'V13R1M500' AND LU.OPERATION_TYPE = 'F' ) -- CREATED BEFORE FL500 ACTIVATED AND TP.REORG_LR_TS < (SELECT LU.EFFECTIVE_TIME FROM SYSIBM.SYSLEVELUPDATES LU WHERE 1 = 1 AND LU.FUNCTION_LVL = 'V13R1M500' AND LU.OPERATION_TYPE = 'F' ) -- LAST REORG/LOAD BEFORE FL500 ACTIVATED ORDER BY 1 , 2 , 3 WITH UR FOR FETCH ONLY ;
This query uses the effective timestamp, created timestamp and the last reorg load replace timestamp to filter out all the partitions that do not need to be REORGed or LOAD REPLACEd.
Please also remember you only need to do all this when you have ROW LEVEL locking in data sharing with high CPU p-locks. The red book shows some very impressive CPU savings!
BACK TO THE HOLIDAYS!
Over the last two years we have added and enhanced our Migration HealthCheck a lot. Improvements include testing what happens with DEFINE NO spaces when they were created years and releases ago but would now be externalized. All of this means the output has changed, of course.
TELL ME MORE!
Here’s a list of all the deprecated (and semi-deprecated) items that should be checked and verified at your site:
Use of SYNONYMS
Use of HASH objects
Use of segmented spaces
Use of classic partitioned objects (not using table based partitioning)
Use of simple spaces
Use of six-byte RBA
Use of BRF
Use of LARGE objects (This is semi-deprecated)
SQL EXTERNAL Procedures
UNICODE (VARBIN Columns)
Old RLF table defs
Old PLAN_TABLE defs
Old bound packages in use in the last 548 days
Direct bound DBRMs (Yes they can still exist!)
ANYTHING ELSE?
Well yes! You could also check how many empty implicit databases and how many empty tablespaces you have. While you are scanning your subsystem, it could also be cool to list out all the Db2 subsystem KPIs. What about seeing how many tables you actually have in multi-table tablespaces that, at some point, must also be migrated off into a UTS PBG or UTS PBR tablespace?
WE DO IT ALL!
Our little program does all of this for you. It runs through your Db2 Catalog in the blink of an eye and reports all of the data mentioned above.
WHAT DOES IT COST?
Nothing – It is our freeware for 2022/2023 and you only have to be registered on our website to request it along with a password to run it.
HOW DOES IT LOOK?
Here is an example output from one of my test systems here in Düsseldorf:
Db2 Migration HealthCheck V2.3 for SC1 V12R1M510 started at 2022-12-14-10.56.00 Lines with *** are deprecated features
Number of DATABASES : 594 # of empty DATABASES : 237 # of implicit DATABASES : 385 # of empty implicit DATABASES: 207
Number of TABLESPACES : 4861 of which HASH organized : 0 of which PARTITIONED CLASSIC : 2 *** # Partitions : 32 *** of which SEGMENTED : 294 *** of which SIMPLE : 0 of which LOB : 67 of which UTS PBG : 4467 # Partitions : 4477 of which UTS PBR (Absolute) : 5 # Partitions : 801 of which UTS PBR (Relative) : 6 # Partitions : 756 of which XML : 20
Number of tablespaces as LARGE : 8 *** Number of empty tablespaces : 28 Number of multi-table TSs : 55 # of tables within these : 239 Number of incomplete TS : 1 XXX Number of INSERT ALG 0 TS : 4861 Number of INSERT ALG 1 TS : 0 Number of INSERT ALG 2 TS : 0
Number of tables : 10293 of which ACCELERATOR ONLY : 0 of which ALIASes : 5307 of which ARCHIVEs : 1 of which AUXs : 60 of which CLONEs : 0 of which GTTs : 136 of which HISTORYs : 1 of which MQTs : 1 of which TABLEs : 4765 of which VIEWs : 2 of which XMLs : 20 Number of tables with Audit : 101 Number of tables with Data Cap : 0 Number of tables incomplete : 1 XXX Number of tables with control : 0
Number of RLF DSNRLMT__ tables : 0 of which columns deprecated : 0 Number of RLF DSNRLST__ tables : 1 of which columns deprecated : 0
Number of PLAN_TABLES : 68 of which deprecated : 3 ***
Number of SYNONYMs : 1 ***
Number of UNICODE V11 Columns : 0
Number of PROCEDURES : 110 of which SQL EXTERNAL : 0 of which EXTERNAL : 108 of which NATIVE SQL : 2
Number of FUNCTIONS : 87 of which EXTERNAL TABLE : 38 of which EXTERNAL SCALAR : 42 of which SOURCED AGGREGATE : 0 of which SOURCED SCALAR : 0 of which SQL TABLE : 1 of which SQL SCALAR : 6 of which SYSTEM-GENERATED : 0
Number of Indexes : 23243 of which HASH : 0 of which type 2 : 23210 # of partitioned IXs : 6 # Partitions : 160 of which DPSI : 18 # Partitions : 164 of which PI : 15 # Partitions : 1138 Number of indexes COPY YES : 38 Number of indexes COMPRESS YES : 0
Number of table partitions : 6606 of which DEFINE NO : 2848 of which six byte RBA <11 NFM: 0 of which six byte RBA Basic : 0 of which ten byte RBA : 3759 Number of TP in BRF : 0 Number of TP with COMPRESS Y : 498 Number of TP with COMPRESS F : 0 Number of TP with COMPRESS H : 0 Number of TP with TRACKMOD YES : 2968
Number of index partitions : 24666 of which DEFINE NO : 20140 of which six byte RBA <11 NFM: 0 of which six byte RBA Basic : 0 of which ten byte RBA : 4527
Number of STOGROUPS : 10 Number of non-SMS VOLUMES : 0
Number of PLANs : 54 of which DBRMs direct : 0 # of SQL statements : 0 Number of PACKAGES (total) : 5788 of which VALID = A : 42 of which VALID = H : 0 of which VALID = N : 44 of which VALID = Y : 5702 of which VALID = S : 0 of which OPERATIVE = N : 0 of which OPERATIVE = Y : 5788
Old RELBOUND executed packages : 0
Number of PACKAGES (distinct) : 480
Number of Original PACKAGES : 0 Number of Previous PACKAGES : 0 Number of Phased-out PACKAGES : 0 Total number of PACKCOPY : 0 of which VALID = A : 0 of which VALID = H : 0 of which VALID = N : 0 of which VALID = Y : 0 of which VALID = S : 0 of which OPERATIVE = N : 0 of which OPERATIVE = Y : 0 Number of SQL statements : 441833
Db2 Migration HealthCheck V2.3 for SC10 V12R1M510 ended at 2022-12-14-10.56.03
Db2 Migration HealthCheck ended with RC: 0
Any line with *** at the end means that you have something to do at some point in the future. The names of all the found objects are written to DD card DEPRECAT so you can then start building a „to do“ list. I would start now to slowly „fix“ all of these before it is 03:00 in the morning, someone is migrating to Db2 14 FL 608 and it all goes horribly wrong…
Any line with XXX means that you have an incomplete definition for a tablespace and/or a table. These should be fixed as well, either by completing the definition or dropping the unfinished object(s).
WHAT’S WRONG WITH LARGE?
This is not actually deprecated but any tablespaces marked as LARGE tend to also not have a valid DSSIZE in them. This is fine if you have built a CASE construct to derive the value from the tablespace definition. But what you should do, is an ALTER and a REORG to „move“ the LARGE to a „proper“ tablespace. IBM and 3rd Party Software vendors hate having to remember that ancient tablespaces are still out there!
ALL ON MY OWN?
Naturally not! For example, after all the ALTERs have been done, a lot of the spaces are simply in Advisory REORG pending status and you could use our RealtimeDBAExpert (RTDX) software to automatically generate the required REORGs to action the changes.
SYNONYMS??
Well, you can do them all yourself by reading one of my older newsletters – just remember to watch out for the GRANTs afterwards.
HOW MANY DEPRECATED OBJECTS DO YOU HAVE?
I would love to get screenshots of the output at your sites which I would then all sum up and publish as an addendum to this newsletter. Just so that people can see how many Parrots we all have pining for the fjords!
This month, I am turning over my blog to my colleague Andre Kuerten from Software Engineering’s German Labs based in Düsseldorf, Germany. I challenged him to write a blog all about his experiences as a „first time IDUG EMEA attendee“ and all that that entailed as I thought this would make an interesting read for us all!
I’ll be Back!
Have no fear, dear readers, as I will be back next month with our annual Christmas give-away. The first blog of 2023 will be my comprehensive review of the 2022 IDUG EMEA in Edinburgh and the surprises found there-in.
It begins…
IDUG EMEA 2022 – First Timer Report
Pre-Preparation-Phase:
My firm gave me the chance to go the IDUG EMEA, additionally taking a Saturday workshop to educate myself in all things SQL. Surprisingly, my wife gave approval! Therefore, “the guy from techsupp” that I am, planned the trip to Edinburgh with all the hotel and flight bookings etc.
Saturday:
Unexpectedly, everything went smoothly and so I was standing in front of the Edinburgh International Conference Center (EICC) on Saturday morning, ready for my first IDUG in person after working for more than 15 years in the Db2 business, professionally developing software.
The general plan was for me to learn, or refresh my knowledge, about query optimization and finding the cause for poor performing SQL to be ready to work a little bit more intensively in this area. The first decision made was that I will take part in the “Query Optimization and Tuning Workshop” that will take the complete Saturday, covering themes like statistics, cardinalities, optimizer stuff, query EXPLAIN and strategies for performance tuning.
I entered the EICC and was registered by the very friendly and helpful IDUG employees, got my badge and a bag filled with little goodies – I think the practical value of the umbrella was unbeatable.
When looking around I have to admit that the EICC is a nice venue. Right behind the entrance is a big hall on the ground level which opens up for you, they arranged some high tables to put down your water/coffee, just a few more chairs would have been a good idea. But I was impressed by the sheer size of it all.
Sched is Your Friend!
The rooms all had Gaelic names, you just had to locate them on the map, so everything could be easily found. The Sched App was a perfect addition to the printed schedules, it made it very easy to get the day organized and to know where to go next. I really liked it and the connection to the website.
Workshop – z/OS???
Took the escalators to “Carrick” and got a seat in the workshop, looked around and discovered the usual mix of technical geeks, where the average age seems to be a little low… Additionally, there was no work station or material lying around that we would have to work with during the day (I had been told by the experienced colleagues that I would really have to work at the workshop), so I started to wonder… Chatting with some of the people in the room was fine, and I was glad I was not the only first timer (I must admit that I didn’t apply for a first timer badge, I do have my limits). Then it started. Instead of the expected z/OS hands-on workshop it slowly turned into an LUW daily presentation… At least I was not alone, as another z/OS guy was also not expecting LUW. It had not been made clear at early registration time that this was going to be just an LUW workshop. Anyway, since the topic was “SQL”, there was still valuable information here. So I listened and concentrated and got new ideas about how to start with SQL optimization and where to look first, starting from query optimization basics, discussing some database design alternatives and ending with cardinality estimation.
After a small lunch, taken in the big hall, the afternoon session started and was now going for the optimization of various operations like Scans, Sort, INSERT, UPDATE, DELETE and queries with outer joins, aggregation, distinct, correlated subqueries etc. I just had to take care to keep focused while the knowledge was being distributed. I think this would have been much easier if we could have done some practical exercises.
At the end the feelings about the workshop were a little bit mixed, but overall positive.
The Roy arrives
Starting in the late afternoon, I kept getting status messages from Roy (Boxwell, just in case anybody knows him 😊) who was on his way to Edinburgh, so our team size doubled in the evening.
The Booth…
Since my firm was a vendor at the IDUG I also got some experience from building the booth (where I really have to say thanks to the people from the EICC for all their help and kindness) and running it.
Sunday:
On Sunday the first normal IDUG Sessions were starting, I made it to the initial key-note in the “Pentland Main Auditorium” titled “Why Some Teams Are Successful While Others Struggle”, it was interesting, even though it was not a direct technical approach, it was about the people that you are working with and trusting your team. The auditorium (more like a cinema theater) was half full and they mentioned that we were 350+ onsite visitors which I found a good number, however I was told that there used to be many more in the past.
The next session, “Db2 13 for z/OS and More!” was summing up what I already knew from all the announced Db2 13 features, remarkable was one of the presenters, Haakon Roberts, he really did an excellent job and, looking back, I would say that his accent was the best that I heard during IDUG.
Noteworthy is that you soon get used to listening to speakers with different, strange to me, accents very fast, even if you are not a native speaker. This had been one of my fears beforehand which was, luckily, unfounded.
Back to “Carrick” and into the “Back to Basics: High Performance Application Design and Programming” presentation held by Tony Andrews. I mention him because of a reason: As expected the sessions differed in presentation style, quality of presentation etc., this is what you can tick on the evaluation cards. But the best ones, for me, were the ones where you could feel that the speaker was really deeply involved in the work with Db2 and knew what they were talking about like in this session, I heard a lot about the little things like row size, clustering order, all from a practical view, which was all very useful.
“Do I Really Need to Worry about my Commit Frequency? An Introduction to Db2 Logging” confirmed my impression that the commit frequency is something to worry about, but the afternoon highlight was “COBOL abound”, demonstrating how you can develop in COBOL these days, of course, not only on the mainframe , but using Zowe (which I also use and explore at my firm) and the containers you can get there. This was really fascinating, although a little bit special…
Monday:
Day 3, Monday, I also went to the key-note “Behind The Birth Of An Accidental Enterprise”, covering some history of Db2’s evolution. When talking about the next one, “Getting RID of RID Pool RIDdles”, I have to mention that this was done by two speakers and one of them, Adrian Collett, is known to me, we have worked together with some trial installations. This was one of the big points: To meet people face to face for the first time, or again after the pandemic, especially customers who I have “talked to” for many years via email or telephone. I got the impression from everyone that they liked it very much to attend in person again. The presentation itself shed some light on RID pool monitoring and tuning. Sadly I have to say that this session was one of those that had to “speed up” towards the end (which was not Adrians fault!), so I am really looking forward to getting my hands on the PDFs as some speakers simply ran out of time and then rushed through their presentations. Also the notes taken correspond to slides that I need to see again, so this service (providing the presentations) should be continued for attendees, maybe IDUG could be just a little bit quicker making them available.
The next, very interesting, one was “Access Paths Meet Coding” which gave me practical insights about how to control some basic SQL rules which must be respected and how big the effect of it is in a productive environment.
It should also be mentioned that, in my eyes, the technical equipment provided for the speakers was more than sufficient and the audio control was done by, always available, technical stuff from the congress center making a very good impression.
“Get Cozy with Traces in Db2 for z/OS” reminded me of one way to get worthwhile information about what is going on (or going wrong) on the system.
For the evening, the IBM Db2 appreciation event was announced, so we took a walk after the conference day ended up going to the National Museum. The National Museum was, of course, closed when we arrived, so we ended up waiting in the crowd for something to happen. A bagpiper started to play: a perfect introduction for the evening. Worthy of note was the AC/DC part. Finally we made it to the grand hall, perfect location and ambience, food and drinks really well arranged. Most impressive for me, was the lifetime award for Mr. John Campbell (he had already been honored previously at a keynote). Even I had read a lot from, and about, him (and the respect shown towards him from all of the audience was also good to see). At the end even Roy got an award: he did well as a “newbie” champion. I think they simply forgot to announce him for “some” years. Deserved without question, but why must he get a trophy for his desk that we have to look at (and that is mentioned by him) every single day?
Wednesday:
Back to the IDUG content on the next, and last day, Wednesday:
At lunch time a, from my point of view, very interesting conference ended, giving me a lot of valuable information and “face-to-face” contacts, some minor negative items are normal I guess, but generally I really appreciated it.
So there you have it!
Many thanks to Andre for writing all that up! Coming soon will be Roy’s take on the EMEA 2022 where I go into technical details about the sessions etc.
I hope you enjoyed the guest blog this month and, as always, let me know what you think!
In part two of this newsletter, I wish to bring you up to speed on all the changes in the profile arena from Db2 11 right up until Db2 13.
Filters!
Profiles basically need some sort of „limit“ to show Db2 which things should get which profile, and thus which keyword and attribute. To do this, we use Filters; for the filtering data there is an order of preference:
Multiple profiles?
When more than one profile applies to a thread or connection, the evaluation of the different profiles is not simultaneous. Instead, the profiles are evaluated in the following order, according to the criteria that are specified in the profile:
1. IP address or domain name, in the LOCATION column.
2. Product identifier, in the PRDID column.
3. Role and authorization identifier, in both ROLE and AUTHID columns.
4. Role, in the ROLE column only.
5. Authorization identifier, in the AUTHID column only.
6. Server location name, location alias, or database name, in the LOCATION column.
7. The location name of a requester, for monitored threads from a Db2 for z/OS requester. This is only for MONITOR THREADS and MONITOR IDLE THREADS.
8. Collection identifier and package name, in both COLLID and PKGNAME columns.
9. Collection identifier, in the COLLID column only.
10. Package name, in the PKGNAME column only.
11. Client application name, in the CLIENT_APPLNAME column.
12. Client user identifier, in the CLIENT_USERID column.
13. Client workstation name, in the CLIENT_WRKSTNNAME column.
First Come, First Served!
Only the first evaluated applicable profile is applied. Because the evaluation of multiple profiles is not simultaneous, the number of connections, or threads, on the subsystem might change during the evaluation of multiple profiles. Any profile that specifies a specific value in a particular column has precedence over a profile that specifies a single-byte asterisk value (‚*‘) in the same column.
Destructive Overlap!
Further, each profile entry cannot have overlapping filter categories. From the precedence list there are eight categories formed from the numbers 1, 2, 3 – 5, 6 – 7, 8 – 10, 11 ,12 and 13, otherwise multiple rows must be inserted.
When you have multiple rows with overlapping filters from different categories then Db2 applies them all. Exact values are higher in priority than wildcard (*). As an example, for product id, PRDID, DSN13011 is before DSN* which is before *.
The More the Merrier!
Db2 also assumes that any rows with more filter values are higher priority than rows with some defaults or NULL values.
Finally, if everything is the same in the filter categories, Db2 will take the last inserted as it assumes this is “the most current version”.
Clear as Mud!
As you can easily see, it is very easy to tie yourself up in knots with this system! Good planning and good testing are paramount to a good, glitch-free implementation!
What Was New in Db2 11?
Well, Db2 11 brought in SPECIAL_REGISTER handling to the profile tables which is especially good for remote accessing threads. So you can now issue SET CURRENT APPLICATION COMPATIBILITY or SET CURRENT PACKAGE PATH, for example.
SET What You Want!
SPECIAL_REGISTER in the KEYWORDS column, ATTRIBUTE1 is any of the accepted SET statements, up to a maximum length of 1024 bytes. ATTRIBUTE2 and ATTRIBUTE3 are both NULL. The filtering is also not case sensitive.
Precedence of the SET special register:
1. Special register explicitly set by the application.
2. Special register set through Profile Support as above.
3. Special register set on the connection property level or data source level.
Buyer Beware!
Db2 11 also introduced warnings about not deleting rows from the _HISTORY tables to make sure you only delete rows that are really gone from the “normal” tables.
Additional Details
The MONITOR CONNECTIONS got a _DIAGLEVEL3 added:
MONITOR CONNECTIONS in the KEYWORDS column, ATTRIBUTE1 is a “two part” column value. The first part is either WARNING or EXCEPTION. A warning causes a console message every five minutes depending on the diagnosis level. An exception issues the diagnosis level and fails the connection request. The second part is either not there or it is_DIAGLEVEL1 which issues a DSNT771I console message, _DIAGLEVEL2 which issues a DSNT772I console message with more details every five minutes at most. _DIAGLEVEL3 issues, for a warning, a DSNT773I console message with more thread details for every thread, and for an exception a DSNT774I console message. ATTRIBUTE2 is a positive integer to indicate the threshold for the maximum number of remote connections. It must be less than or equal to CONDBAT. ATTRIBUTE3 is NULL. Filtering is only by the LOCATION column.
MONITOR IDLE THREADS got three new ATTRIBUTE1 values: EXCEPTION_ROLLBACK aborts any active idle threads and issues DSNT771I, EXCEPTION_ROLLBACK_DIAGLEVEL1 which is the same, and EXCEPTION_ROLLBACK_DIAGLEVEL2 with message DSNT772I.
MONITOR THREADS got _DIAGLEVEL3 added, which for an EXCEPTION issues a DSNT774I console message and, depending on the filtering, can be queued or suspended. WARNING issues the console message DSNT773I for every thread that exceeds the profile threshold.
Updated Info!
The info table about which columns can filter etc. got an overhaul with the note “The value is not case sensitive” for all values for MONITOR CONNECTIONS, MONITOR THREADS, MONITOR IDLE THREADS and SPECIAL_REGISTER.
IP6 Support!
It was also in Db2 11 that IPv6 got supported in the LOCATION field. So, it was now an IP Address: IPv4 dotted-decimal, or an IPv6 colon-hex, or a Domain Name, or a Location name.
What Was New in Db2 12?
In Db2 12, some new KEYWORDS options were introduced:
MONITOR ALL CONNECTIONS in the KEYWORDS column, ATTRIBUTE1 is a “two part” column value. The first part is either WARNING or EXCEPTION. A warning causes a console message every five minutes, depending on the diagnosis level. An exception issues the diagnosis level and fails the connection request. The second part is either not there or it is_DIAGLEVEL1 which issues a DSNT771I console message, _DIAGLEVEL2 which issues a DSNT772I console message with more details every five minutes, at most, and _DIAGLEVEL3 which issues a DSNT773I for WARNING and DSNT774I for EXCEPTION console message with more details. ATTRIBUTE2 is a positive integer to indicate the threshold for the total cumulative number of remote connections from all application servers . It must be less than or equal to CONDBAT. ATTRIBUTE3 is NULL. Filtering is only by the LOCATION column which must contain ‘*’, ‘:::0’ or ‘0.0.0.0’
MONITOR ALL THREADS in the KEYWORDS column, ATTRIBUTE1 is a “two part” column value. The first part is either WARNING or EXCEPTION. A warning causes a console message every five minutes, depending on the diagnosis level. An exception issues the diagnosis level and can cancel the thread, depending on the filtering criteria. Otherwise the thread is queued. The second part is either not there or it is _DIAGLEVEL1 which issues a DSNT771I console message, and _DIAGLEVEL2 which issues a DSNT772I console message with more details. _DIAGLEVEL3 issues a DSNT773I for WARNING and DSNT774I for EXCEPTION console message. ATTRIBUTE2 is a positive integer to indicate the threshold for the total cumulative number of active server threads. It must be less than or equal to MAXDBAT. ATTRIBUTE3 is NULL. Filtering is only by the LOCATION column which must contain ‘*’, ‘:::0’ or ‘0.0.0.0’.
Variable Support
GLOBAL_VARIABLE in the KEYWORDS column, ATTRIBUTE1 is a SET statement for a global variable. E.g. SET SYSIBMADM.GET_ARCHIVE = ‘Y’ or, if you are at Db2 12 FL507 or higher, SET SYSIBMADM.MAX_LOCKS_PER_TABLESPACE = 9000. See the SET documentation in the SQL Reference for more details. ATTRIBUTE2 and ATTRIBUTE3 are both NULL. These are only valid for remote applications.
SHARE_LOCKS in KEYWORDS column, ATTRIBUTE1 column contains a property that applies to global transactions in an RRS context, such as CICS through the External CICS interface. The property applies only to remote applications. The value must be in the following format: PROCEDURE_LIST=aaaa,bbbb,… each of the listed procs cannot be an external SQL proc and not a three part name. Maximum length is 1024 bytes. ATTRIBUTE2 and ATTRIBUTE3 are both NULL.
What Is New in Db2 13
FL500 introduced two extra keywords:
RELEASE_PACKAGE in the KEYWORDS column, ATTRIBUTE1 is COMMIT. ATTRIBUTE2 NULL means this is for remote threads only. 1 applies to local threads only (applies at package load) and 2 profile applies to both local and remote threads. ATTRIBUTE3 is NULL.
SPECIAL_REGISTER in the KEYWORDS column, ATTRIBUTE2 NULL means this is for remote threads only. 1 applies to local threads only (applies at package load) and 2 profile applies to both local and remote threads. Note that only SET CURRENT LOCK TIMEOUT (But not the WAIT, MODE or TO syntax) is currently supported for local threads.
FL 501 introduced local global variable support:
GLOBAL_VARIABLE in the KEYWORDS column, ATTRIBUTE2 NULL means this is for remote threads only. 1 applies to local threads only (applies at package load), and 2 profile applies to both local and remote threads. Note that only SET SYSIBMADM.DEADLOCK_RESOLUTION_PRIORITY = xxx is currently supported for local threads.
The Future Is Bright!
It must be assumed that more and more things will end up in these profiles and it will get more and more interesting to use them, but the major problem is that they are not really transparent. It is very easy to incorrectly set them up and they are tricky, if not impossible, to test. All that being said, they are a very important tool in the tool-box of the modern, agile, DBA!
Examples
Use Case 1 : Evaluate a parameter change
You want to evaluate the impact of a modification at a system or application parameter. You can create a specific profile, with the values you want to activate, and an action level of type WARNING. After starting the new profile, follow the message DSNT773I to monitor the future impact of your modification, without impacting the subsystem behaviour.
Use Case 2 : Avoid to adapt attributes of your NULLID Collection
For dynamic SQL, it is not recommended to adapt parameters (APPLCOMPAT, CONCENTRATESTMT …) of the NULLID collection, as it would impact every client working with the default collection. So, if you want an application to use specific options, you could duplicate the packages of the NULLID collection in a specific collection with the appropriate bind parameters. Defining a profile that identifies the application, you can redirect to the new COLLID with the use of the special register PACKAGE PATH. Should your new settings not be optimal, a simple stop of the profile will restore the situation.
Use Case3: High Performance DBAT but *not* everywhere!
The problem: NULLID being used for all remote access and you wish to use High Performance DBATs for some of them but not all. The solution: Create a new collection, called e.g. HIGHPERDBAT, and bind into it any and all of the packages you want available for High Performance DBAT (so also with RELEASE(DEALLOCATE) naturally!) Insert a Profile Id with a filter for the criteria you wish for, (see earlier in this blog). Then insert an attribute keyword of SPECIAL_REGISTER with ATTRIBUTE1 to be SET CURRENT PACKAGE PATH = ‚HIGHPERDBAT‘ If the profile is started, then at next connection time, this new collection will be honored. If something goes awry, and you start getting DBAT problems, simply disable this profile entry and you are done!
Cool huh?
Remember that you must also *allow* High Performance DBATs by running with DDF parameters CMSTAT set to „INACTIVE“ and PKGREL set to „BNDOPT“ or „BNDPOOL“.
As always, I would love to hear any comments or criticism about this topic!
This month I begin a two-part topic because it is just too large to do in one blog entry!
In the Beginning
The DSN_PROFILE_TABLE was introduced sometime in DB2 V8, but it was not until DB2 9 that it started to be used for system profiling when IBM introduced three new commands: DISPLAY PROFILE, START PROFILE and STOP PROFILE. This first appearance of PROFILES was a bit limited and could control only a few ZPARMs – and four of those just for EXPLAIN purposes.
How does/did it look?
To get it working, you must first create all the required tables and indexes. (The DDL is in the db2hlq.SDSNSAMP member DSNTIJSG.) In bold and italics are the DB2 10 and higher versions:
SYSIBM.DSN_PROFILE_TABLE CREATE TABLE SYSIBM.DSN_PROFILE_TABLE ( "AUTHID" VARCHAR(128) ,"PLANNAME" VARCHAR(24) ,"COLLID" VARCHAR(128) ,"PKGNAME" VARCHAR(128) ,"LOCATION" "IPADDR" VARCHAR(254) ,"PROFILEID" INTEGER NOT NULL PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY ,"PROFILE_TIMESTAMP" TIMESTAMP NOT NULL WITH DEFAULT ,"PROFILE_ENABLED" CHAR(1) NOT NULL DEFAULT 'Y' ,"GROUP_MEMBER" VARCHAR(24) ,"REMARKS" VARCHAR(762) ,"ROLE" VARCHAR(128) ,"PRDID" CHAR(8) ,"CLIENT_APPLNAME" VARCHAR(255) ,"CLIENT_USERID" VARCHAR(255) ,"CLIENT_WRKSTNNAME" VARCHAR(255) ); CREATE UNIQUE INDEX SYSIBM.DSN_PROFILE_TABLE_IX_ALL ON SYSIBM.DSN_PROFILE_TABLE ( "PROFILEID" ); CREATE INDEX SYSIBM.DSN_PROFILE_TABLE_IX2_ALL ON SYSIBM.DSN_PROFILE_TABLE ( "PROFILE_ENABLED" ,"AUTHID" ,"PLANNAME" ,"COLLID" ,"PKGNAME" ,"LOCATION" "IPADDR" ,"PRDID" ,"ROLE" ,"CLIENT_APPLNAME" ,"CLIENT_USERID" ,"CLIENT_WRKSTNNAME" ,"GROUP_MEMBER" ,"PROFILE_TIMESTAMP" DESC );
SYSIBM.DSN_PROFILE_HISTORY – Same columns as DSN_PROFILE_TABLE apart from
REMARKS -> STATUS VARCHAR(254) and no index.
SYSIBM.DSN_PROFILE_ATTRIBUTES CREATE TABLE SYSIBM.DSN_PROFILE_ATTRIBUTES ( "PROFILEID" INTEGER NOT NULL REFERENCES SYSIBM.DSN_PROFILE_TABLE ON DELETE CASCADE ,"KEYWORDS" VARCHAR(128) NOT NULL ,"ATTRIBUTE1" VARCHAR(1024) ,"ATTRIBUTE2" INTEGER ,"ATTRIBUTE3" FLOAT ,"ATTRIBUTE_TIMESTAMP" TIMESTAMP NOT NULL WITH DEFAULT ,"REMARKS" VARCHAR(762) ); CREATE UNIQUE INDEX SYSIBM.DSN_PROFILE_ATTRIBUTES_IX_ALL ON SYSIBM.DSN_PROFILE_ATTRIBUTES ( "PROFILEID" ,"ATTRIBUTE_TIMESTAMP" DESC ,"KEYWORDS" ,"ATTRIBUTE1" ,"ATTRIBUTE2" ,"ATTRIBUTE3" );
SYSIBM.DSN_PROFILE_ATTRIBUTES_HISTORY same columns as DSN_PROFILE_ATTRIBUTES apart from
REMARKS -> STATUS VARCHAR(254) and no index.
Notice the RI between the DSN_PROFILE_ATTRIBUTES and DSN_PROFILE_TABLE keyed on PROFILEID. Also notice that there are no indexes on the HISTORY tables and also no RI.
So What Could You Do?
With this new functionality you could use a profile to override four ZPARMs, namely NPGTHRSH, OPTIOWGT, STARJOIN and SJTABLES. To do so, you first inserted a row into the DSN_PROFILE_TABLE with some sort of filter, at this time only COLLID and PKGNAME, and then one or more inserts in the DSN_PROFILE_ATTRIBUTES table using the PROFILEID that you either just used, or got generated for you, in the DSN_PROFILE_TABLE using the KEYWORDS column and ATTRIBUTEn column(s).
Always on?
The column PROFILE_ENABLED in the DSN_PROFILE_TABLE informs Db2 whether or not to consider this profile when the START PROFILE command is issued. Setting it to N puts all of this profile’s records “to sleep”.
Not Just ZPARMs
It also enabled three global changes (no filters allowed) for BPname, MAX_RIDBLOCKS and SORT_POOL_SIZE. All of these are just for modelling production systems in test to then get a better, more accurate, EXPLAIN result and have *no* effect on the actual system at all.
Finally, IBM added some Accelerator-only support which had to be done with IBM involved.
Interestingly enough, there was a complete chapter about using profiles to monitor and report on SQL but there was also an update to the docu:
Important: The use of profile tables to monitor and capture information about the performance of SQL statements is deprecated, and not recommended.
So, I will not even bother going into detail about the monitor settings.
What Was the Difference?
The major difference between the SQL and ZPARM settings, was the ability to use different filter column values like AUTHID or IPADDR/LOCATION.
The DSN_PROFILE_HISTORY has the same columns as the DSN_PROFILE_TABLE, except that REMARKS is called STATUS and gets a value set by the START PROFILE command. Basically, a string that starts with REJECTED – or ACCEPTED – and then a text string describing why the profile was, or was not, accepted for use.
What’s in an ATTRIBUTE?
The DSN_PROFILE_ATTRIBUTES table contains the option that should be overridden when the Profile is active and the filtering allows it. The columns of interest are KEYWORDS and the three ATTRIBUTEn columns.
BUFFERPOOL Modelling
BPname (where name is any of the valid names like 0 through 49 or 32K1 through 32K9 etc.) in the KEYWORDS column. ATTRIBUTE1 and ATRIBUTE3 are set to NULL and ATTRIBUTE2 contains a positive integer value for the size of the BUFFERPOOL (for production modelling).
RIDPOOL Modelling
MAX_RIDBLOCKS in the KEYWORDS column, ATTRIBUTE1 and ATTRIBUTE3 are set to NULL, and ATTRIBUTE2 contains a value from 0 to the maximum value that you can set MAXRBLK in that subsystem (for production modelling).
STARJOIN Control
STAR JOIN in the KEYWORDS column, ATTRIBUTE2 and ATTRIBUTE3 are set to NULL, and ATTRIBUTE1 set to DISABLE or ENABLE.
MIN STAR JOIN TABLES in the KEYWORDS column, ATTRIBUTE1 and ATTRIBUTE3 are set to NULL, and ATTRIBUTE2 contains a value from 3 to 225.
INDEX ACCESS Control
NPAGES THRESHOLD in the KEYWORDS column, ATTRIBUTE1 and ATTRIBUTE3 are set to NULL, and ATTRIBUTE2 contains one of the following values:
-1 use index access if possible
0 access path based on cost, the normal way Db2 works
1 to nnnn Db2 should use index access on tables for which the total number of pages (NPAGES) is less than nnnn. Make sure that your Db2 Catalog statistics are up to date before you specify a value of 1 or greater.
IO Control
IO WEIGHTING in the KEYWORDS column, ATTRIBUTE2 and ATTRIBUTE3 are set to NULL, and ATTRIBUTE1 is set to DISABLE or ENABLE (deprecated in DB2 10).
SRTPOOL Modelling
SORT_POOL_SIZE in the KEYWORDS column, ATTRIBUTE1 and ATTRIBUTE3 are set to NULL, and ATTRIBUTE2 set to a positive integer up to the maximum value of SRTPOOL. That is the new SRTPOOL (for production modelling).
Production Modelling
In this case, the EXPLAIN output got changed to output which PROFILE value was active at the time of the EXPLAIN. The REASON column in the DSN_STATEMNT_TABLE gets set to “PROFILEID nnnn” for the profile number that was active at the time of the EXPLAIN.
When Was this Done?
The DSN_PROFILE_ATTRIBUTES_HISTORY has the same columns as the DSN_PROFILE_ATTRIBUTES_TABLE except that REMARKS is called STATUS and gets a value set by the START PROFILE command. Basically, a string that starts with REJECTED – or ACCEPTED – and then a text string describing why the profile was, or was not, accepted for use.
So that was it for DB2 9 – not that much but a very good start if you ask me!
System Profile Monitoring
Then in DB2 10 came “system profile monitoring”, which is where this system got very useful indeed! It then got the ability to Monitor Connections, Monitor Threads and Monitor Idle Threads.
New Keywords for Connections and Threads!
MONITOR CONNECTIONS in the KEYWORDS column, ATTRIBUTE1 is a “two part” column value. The first part is either WARNING or EXCEPTION. A warning causes a console message every five minutes depending on the diagnosis level. An exception issues the diagnosis level and rejects any new incoming connection requests. The second part is either not there or it is _DIAGLEVEL1 which issues a DSNT771I console message and _DIAGLEVEL2 which issues a DSNT772I console message with more details. ATTRIBUTE2 is a positive integer to indicate the threshold for the maximum number of remote connections. It must be less than or equal to CONDBAT. ATTRIBUTE3 is NULL. Filtering is only by the LOCATION column.
MONITOR THREADS in the KEYWORDS column, ATTRIBUTE1 is a “two part” column value. The first part is either WARNING or EXCEPTION. A warning causes a console message every five minutes depending on the diagnosis level. An exception issues the diagnosis level and can cancel the thread depending on the filtering criteria otherwise the thread is queued. The second part is either not there or it is _DIAGLEVEL1 which issues a DSNT771I console message and _DIAGLEVEL2 which issues a DSNT772I console message with more details. ATTRIBUTE2 is a positive integer to indicate the threshold for the maximum number of server threads. It must be less than or equal to MAXDBAT. ATTRIBUTE3 is NULL. Filtering on nearly all columns is allowed.
Db2 11 Docu Update
In Db2 11, an extra bit of documentation was added when filtering by Collection identifier, package name, client user name, client application name or client workstation name. When the total number of queued and suspended threads exceeds the threshold, Db2 fails subsequent SQL statements and returns SQLCODE -30041 to the client.
For example, suppose that a profile for a package is started. That profile uses ATTRIBUTE2=2. If five threads request to run the package, two threads run concurrently, two threads are queued and suspended, and Db2 fails the SQL statements for the fifth thread.
And Finally IDLE?
MONITOR IDLE THREADS in the KEYWORDS column, ATTRIBUTE1 is a “two part” column value. The first part is either WARNING or EXCEPTION. A warning causes a console message every five minutes, depending on the diagnosis level. An exception issues the diagnosis level and cancels the idle thread. The second part is either not there or it is _DIAGLEVEL1 which issues a DSNT771I console message or _DIAGLEVEL2 which issues a DSNT772I console message with more details or WARNING_MESSAGE_FOR_IDLE_TIMEOUT (only for WARNING) which issues DSNT771I and/or DSNT773I. ATTRIBUTE2 is a positive integer to indicate the threshold for the maximum number of seconds an active server thread can stay idle.
That’s all for this month, next month I will go into detail about the Filters, the new stuff In Db2 11, 12 and 13 as well as examples of different things you can do nowadays.
As always I would love to hear any comments or criticism about this topic!
This month is a quick run through of the z/OS presentations from the IDUG NA22 Boston – the first in-person event in three years!
It was great to actually meet and greet real people again! The only problem I had, was the extreme cold of the Hotel rooms: The expo was set to be like a freezer and, for a European person whose normal air-conditioning is an open window, it was a pretty uncomfortable experience.
If you were there physically, or even virtually, you can now download all the PDFs from all the tracks, so I have grabbed all the A, B, E Tracks and half of the F and G Tracks (Only the z/OS relevant stuff for me!)
Off we Go in Alphabetical Sequence
A01 Create value from data and where the DBA counts is an excellent overview of the modern world and where data and DBAs sit. It also contains a bunch of very nice SQL that you can indeed simply run in your shops as cut-and-paste. (I did!) access content at IDUG.org (appropriate IDUG access required)
A02 was a very good intro into all the performance changes in Db2 12 and 13 (Check out my Db2 13 blog post as well for that matter!) and also on the hardware side with z15 and the brand new z16 box! access content at IDUG.org (appropriate IDUG access required)
A03 & A04 were all about AI, including a bunch of example SQLs for the three new AI BiFs in Db2 13 and how to get it all working, as well as Distributed Connection control. access content at IDUG.org (appropriate IDUG access required) access content at IDUG.org (appropriate IDUG access required)
A05 was all about getting „value“ from your Db2. Are you really using all the „newest“ functionality that you could? access content at IDUG.org (appropriate IDUG access required)
A06 from Haakon Roberts was an excellent update all around Utilities and latest APARs. The highlight being, at least for me, the ICLIMIT TAPE for REORG which finally enables easy migration to UTS PBR RPN Tablespaces. The heads up about the LOAD FORMAT DELIMITED was also good! access content at IDUG.org (appropriate IDUG access required)
A07 concerned The Trilogy of originating SQLs and how to measure and tune them. At the end was an extra part called „Additional Tuning“ that is well worth a read, as it fully explains the internal Db2 data flow from SQL to RDS to DM to Media manager. access content at IDUG.org (appropriate IDUG access required)
A08 was all about SWAT Tales and had some great interaction! The best bit was one attendee stated that his Db2 system is going through 93 x 768 GB log datasets in less than 6 hours… The important take-away was to keep up to date with PTFs, especially HIPERs (Here you can subscribe to my monthly APAR reports to aid in this), and make sure you have enough logs! Plus, take care with high performance DBAT usage. Finally: Watch out for over- and mis-use of PBG spaces! access content at IDUG.org (appropriate IDUG access required)
A10 was all about migrating to UTS and to Db2 12 – Do not underestimate the time and effort required to do this! access content at IDUG.org (appropriate IDUG access required)
A11 contained details about using the RTS to work as a „monitor“ enabling you to get a different view of GETPAGES for example. access content at IDUG.org (appropriate IDUG access required)
A12 tied in with the A01 presentation and was all about Dynamic SQL problems and solutions including a nice way to „purge“ single SQLs from the DSC! Included some very interesting SQLs to calculate your DSC KPIs. access content at IDUG.org (appropriate IDUG access required)
A13 was all about configuring Data Sharing as well as solving some common issues with it. It was a great intro to everything DS. Plus, it contained a list of new and improved things that came along in Db2 12 and 13. access content at IDUG.org (appropriate IDUG access required)
A14 was all about inactive data impacting your performance. A very interesting topic that all sites probably have an issue with without really knowing it! Archive Enabled Tables could be very useful… Towards the end were a couple of nice features in Db2 with UNION ALL. access content at IDUG.org (appropriate IDUG access required)
A15 was a journey through TRACES, SMF and IFCIDs. If you ever wanted to know about any of these things then here’s the best starting place! access content at IDUG.org (appropriate IDUG access required)
A16 launched Python at the DBAs and sysprogs! Scary stuff! All about installing Python on z/OS and latest bug fixes etc etc. My favorite bit was the „disable auto commit“ and „remember to commit before disconnect“! access content at IDUG.org (appropriate IDUG access required)
B-Track
B01 was all about getting prepared for Db2 13. Starting with a review of all the FLs of Db2 12 right up to FL510 which is the major prereq for Db2 13, of course! access content at IDUG.org (appropriate IDUG access required)
B02 contained a ton of details all about the „Black hole“ of Db2 statistics – Page Latch Suspensions, plus a very handy list of how to fix these suspensions – if at all possible… access content at IDUG.org (appropriate IDUG access required)
B03 took you into the first steps of the Machine Learning (ML) world. Started off with penquins and then I got sort of lost … 🙂 access content at IDUG.org (appropriate IDUG access required)
B04 was another migration session about getting from Db2 12 FL501 to Db2 13, this time incorporating Deprecated functions and Incompatible changes etc. access content at IDUG.org (appropriate IDUG access required)
B05 gave us four different ways to migrate away from multi-table tablespaces to PBGs. From Unload/Drop/Create/Load, MOVE TABLE (Db2 12 FL508), create „%_new“ tables => INSERT from original => rename original to „%_old“ => rename „%_new“ to original => drop „%_old“, and lastly, using a vendor tool to do the work for you! access content at IDUG.org (appropriate IDUG access required)
B06 was all about the pre-migration query DSNTIJPE and what you do, or don’t do, with the resulting 23 odd reports. access content at IDUG.org (appropriate IDUG access required)
B07 showed how MasterCard monitors any and all Db2 Alerts to take proactive actions before things go pear-shaped. This includes disk space, messages, sql codes, access path changes, memory, storage, DDF, physical media limits (size, extents, volumes etc.) There is a very handy full list of „things to monitor“ at the end of the presentation as well. Check out the RTDX SAX tool timings! access content at IDUG.org (appropriate IDUG access required)
B08 Explain explained – Complete introduction as to how the Db2 Optimizer makes its cost-based decision. At the end were a couple of nice „best practices“ slides summing it all up very well. access content at IDUG.org (appropriate IDUG access required)
B10 Db2 for z/OS housekeeping. This was all about a methodology for REORG/RUNSTATS/REBIND. The interesting take away here was the idea to *never* run a RUNSTATS based soley on RTS counters from the last RUNSTATS. In other words, just do a RUNSTATS when you are doing a REORG. access content at IDUG.org (appropriate IDUG access required)
B11 was all about client configuration and was a cross-platform presentation (naturally!) It contained all you need to know about the setup and installation and use of the db2cli among many other things! access content at IDUG.org (appropriate IDUG access required)
B12 had Tips for DBAs and programmers to help reduce costs – Always a good topic! In here was also a nice tip about keeping up to date with your COBOL compiler! access content at IDUG.org (appropriate IDUG access required)
B13 got secure on us by using Multi-factor Authentication for Db2 z/OS. This included setting up MFA and examples of when it works or does not work. access content at IDUG.org (appropriate IDUG access required)
B14 carried on the security theme by going into detail about how to protect yourself from Ransomware attacks. Here multi-layer protection is the best – MFA, Pervasive encryption, Separation of duties (SECADM usage…), Controlling access to Db2 datasets etc. etc. access content at IDUG.org (appropriate IDUG access required)
B15 came back to more „normal“ territory about stopping runaway applications by using the RLF tables DSNRLSTxx and/or DSNRLMTxx, including a nice selection of examples to give you a head start. access content at IDUG.org (appropriate IDUG access required)
B16 presented a way to use MS Excel to help in analyzing performance data. A nice introduction into getting data down to the PC and then using advanced plug-ins like ToolPak. access content at IDUG.org (appropriate IDUG access required)
E-Track
E01 was all about the Optimizer and its various access path and resultant performance. Tons of notes all about access paths make this well worth a read! access content at IDUG.org (appropriate IDUG access required)
E02 was a recap of Continuous Delivery, going over the why’s and how’s including vendor responses, and then ran through all the FL levels that we have so far had. access content at IDUG.org (appropriate IDUG access required)
E03 SQL Performance for application developers was an introduction, with examples, about what an application developer should know about SQL at a minimum! access content at IDUG.org (appropriate IDUG access required)
E04 was one of my presentations all about esoteric Db2 functions – Db2 stuff that is rarely used or not well understood. Covering FIT/FTB, Spatial Indexes, REGEX, Clones and scrollable cursors. All good fun! access content at IDUG.org (appropriate IDUG access required)
E05 was all about IBM Db2 Developer Extension and Db2 Administration Foundation – Obviously the live demos are missing but it gives you a good idea! access content at IDUG.org (appropriate IDUG access required)
E06 Advanced Db2 Performance Tuning for Beginners – the title says it all. Six objectives done great by Joe – It covered both LUW and z/OS and contained a „Steps to Solve the Crime“ section. access content at IDUG.org (appropriate IDUG access required)
E07 was a run through of all good stuff we got in Db2 12 including comparisons between 11 and 12 and an introduction to RESTful calls. access content at IDUG.org (appropriate IDUG access required)
E08 was a plea for testing. How to generate test data and how to actually test and measure. Included examples of PLSQL to generate test data, and proposes the mantra to Measure and Monitor what you are doing and what you have done. access content at IDUG.org (appropriate IDUG access required)
E10 was another one of my presentations where I go into detail about all currently deprecated features of Db2 12 and 13. It gave pages of SQL that you can use to check your own Db2 subsystem, or you can download our freeware MHC2 Migration HealthCheck program that does it all for you. (This is continually updated whenever anything new is deprecated, by the way!) access content at IDUG.org (appropriate IDUG access required)
E11 all about „Things your DBAs hear“. A very good, light-hearted look at the „normal craziness“ of being a DBA these days! access content at IDUG.org (appropriate IDUG access required)
E12 A DBA’s epic journey covered how to deal with SLOW SQL and then the taming of four common SQL „problem statements“. access content at IDUG.org (appropriate IDUG access required)
E13 was a very apt Session code! All about the usage and requirement of RECOVER these days. It covered why you should be able to do it and preparing for it as it will be required at some time… access content at IDUG.org (appropriate IDUG access required)
E14 was a modernization call for Db2 stored procedures and RESTful services. Examples were included as well as Hints & Tips especially around DSNULI, Parameters and File usage of existing stored procs. access content at IDUG.org (appropriate IDUG access required)
E15 covered how to fall back from a schema change as quickly as possible! Use of high speed flash copies to a clone show you a way to handle this. access content at IDUG.org (appropriate IDUG access required)
E16 An overview of a „true“ HTAP system. This showed how using an accelerator processing the logs you can indeed get to the Holy Grail of Transactional and Analytical processing happening at the same time on the same data. access content at IDUG.org (appropriate IDUG access required)
F-Track
F01 was all about JAVA performance – and we all need better JAVA performance these days! Kudos for the callouts on Spring Batch and Hibernate. access content at IDUG.org (appropriate IDUG access required)
F04 Back to basics with Db2 Buffer Pools – Covered everything you would ever need to know about Db2 Buffer Pools! Set-up, Monitor, Configure and Tune. access content at IDUG.org (appropriate IDUG access required)
F06 explained the use of Indexes, how they look internally and all about performance, including when to REORG them at the optimal moment. access content at IDUG.org (appropriate IDUG access required)
F07 SQL went crazy using Pivot and Transpose, some for z/OS some for LUW – a real smorgasbord of SQLs! access content at IDUG.org (appropriate IDUG access required)
F11 contained a ton of detail about connecting Clients to Servers which is not quite as straightforward as some people think… access content at IDUG.org (appropriate IDUG access required)
F12 Ran through the Db2 Catalog and Directory as it was, as it is and how to migrate to Db2 13. access content at IDUG.org (appropriate IDUG access required)
F13 covered how to use the TRACE facility of Db2 including all the information you could ever want to know about which Trace is which class is which IFCID… access content at IDUG.org (appropriate IDUG access required)
F14 was all about the perennial problem of Db2 logging and Commit frequency including full information about what is logged, what is written in the BSDS and adding/removing Active Logs. access content at IDUG.org (appropriate IDUG access required)
F16 was DSC (Dynamic Statement Cache) usage, how it actually works, how to improve it and a quick glimpse into using the IDAA (Accelerator). access content at IDUG.org (appropriate IDUG access required)
G-Track
G02 discussed the requirement for a Next Generation DBA. Having fewer people with the skills drives the demand for AI to help out. access content at IDUG.org (appropriate IDUG access required)
G03 was very interesting as it was all about setting up Encryption through the SECPORT which is becoming standard these days. Full of configuration Hints & Tips. Also contained a full example of running NETSTAT and loading the output up into a Db2 table every few minutes so you can analyze who is accessing using just the TCPPORT – Heaven! access content at IDUG.org (appropriate IDUG access required)
G05 AI again but this time protecting your systems from bad DBAT problems. access content at IDUG.org (appropriate IDUG access required)
G06 Running through old Db2 releases up to current with special regard to the problem of RECOVERY and availability as they have changed over the years. access content at IDUG.org (appropriate IDUG access required)
G12 went into depth about cutting back-up costs by using a hybrid-cloud multi-temperature storage system. Using Db2 for z/OS Data Gate delivered through IBM Cloud Pak for Data enables all of this. The big idea here, was to take your rarely used archive data and move it into the cloud. access content at IDUG.org (appropriate IDUG access required)
G13 brought up the use of Redirected Recovery to ease your fears of recovery. You can simply validate, with no system interruptions of any kind, whether or not you are indeed even recoverable and, most importantly, how long it really takes. access content at IDUG.org (appropriate IDUG access required)
G14 went into the IBM Cloud Pak world again, this time with virtualization being the main theme. The fact that the data lake has „dried up“ due to various problems (GDPR being amongst them!) leads to virtualization being the way forward. DaaS – Data as a Service. access content at IDUG.org (appropriate IDUG access required)
G16 and finally… we get to the last one, and it is a *very* big one all about Db2 Security Best Practices from David Beulke. An absolute treasure trove of Do’s and Do Not’s all related to the world of Audit. Our WLX Audit also gets a shout out so well done for that! access content at IDUG.org (appropriate IDUG access required)
Summary
All in all it was a vast amount of information to try and take-in. IDUGs are always places of learning and I always learn stuff – I am now really looking forward to the IDUG EMEA 2022 in Edinburgh coming up from October the 22nd through to the 26th.
I hope to see you there!
TTFN,
Roy Boxwell
Um unsere Webseite für Sie optimal zu gestalten und fortlaufend verbessern zu können, verwenden wir Cookies. Lehnen Sie Cookies ab, stehen einige Funktionen der Website nicht zur Verfügung. Weitere Informationen hierzu erhalten Sie in unserer Datenschutzerklärung.AkzeptierenAblehnenDatenschutzerklärung