This month I wish to bring along a few things of future interest. It all started in Valencia at the IDUG EMEA in 2024, shortly before the catastrophic floods. Haakon Roberts held his “trends and directions” presentation at the very beginning and this text was in his slide deck on page 4:

Now, we all know that IBM *never* announces “Db2 V14 is coming soon!” But they do talk about Vnext, and it is pretty obvious that this list will stop you migrating from Db2 13 to Db2 14 if any of these items exist or, even worse, are in use at your shop.
What Can You Do?
Well, way back in 2020, I wrote a Migration HealthCheck for Db2 z/OS program as our yearly “give-away” and guess what? It does all the stuff in that list *apart* from VTAM. Not only that, but in the intervening years Audit has grown and grown in importance. Then, in January 2025, DORA came out, for which I wrote another yearly “give-away” called SecurityAudit HealthCheck for Db2 z/OS . This checks everything an auditor would like to have checked, and *also* checks for VTAM/SNA usage in the Communication Database (CDB).
VTAM/SNA??
Cast your mind back about 25 years or so, and you might well remember that TCP/IP was some weird new-fangled way of sending “packets of information” – Not something responsible mainframers did at all! All we had was VTAM/SNA and 3270 with green screens – It was (is!) enough for us!
The Cheque is in the Post …
These days, VTAM/SNA has long overstayed its welcome, as it was a “I trust you” style of communication. The rationale was, “If you have logged onto one Db2 system, I must trust you on any other Db2 system – Who would lie to me?” So, it is not recommended any more and, in fact, with DORA and other Audit requirements it is a *bad* idea to even allow it to be “on its perch” – it must be carried out and buried!
When the B was big!
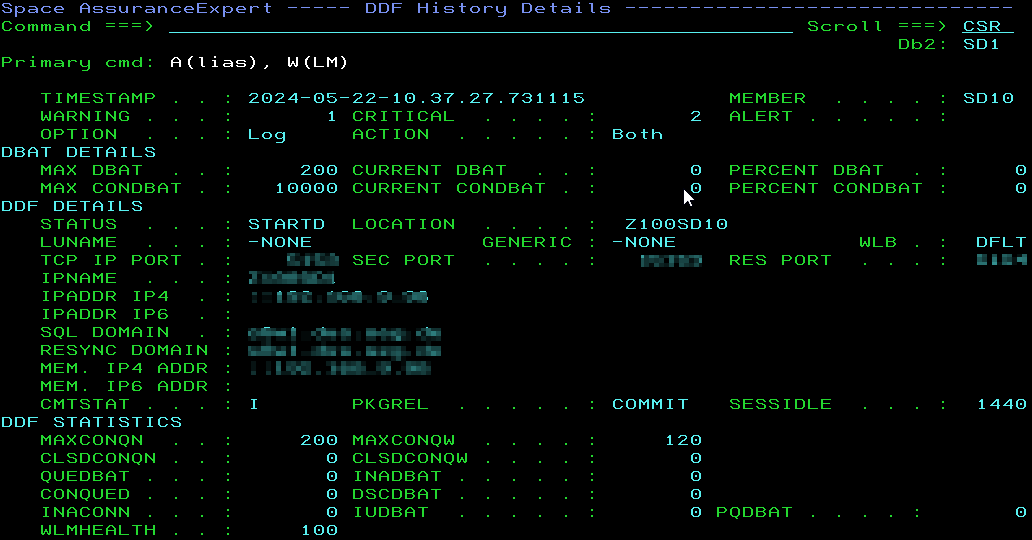
Back in DB2 V9 (remember when the B was BIG?), IBM brought in the IPNAME “ZPARM” to enable the complete disabling of VTAM/SNA communication in the DDF as it is was known, even way back then, to be an inherent security risk.
Why “ZPARM”?
Well, here is another twist to the story: IBM introduced this like a ZPARM but it is actually a parameter of the DDF and is stored in the Bootstrap Dataset (BSDS). So, run a DSNJU004 and you might see something like this:
LOCATION=xxxxxxxx IPNAME=(NULL) PORT=nnnn SPORT=nnnnn RPORT=nnnn
ALIAS=(NULL)
IPV4=xxx.xxx.xxx.xxx IPV6=NULL
GRPIPV4=xxx.xxx.xxx.xxx GRPIPV6=NULL
LUNAME=xxxxxxxx PASSWORD=(NULL) GENERICLU=(NULL)
Here you can plainly see the IPNAME=(NULL) telling you it is not set and thus allows VTAM/SNA.
When DDF starts, it reports all of its parameters, slightly differently of course just to be awkward, in the xxxxMSTR output:
12.15.25 STC04347 DSNL003I -xxxx DDF IS STARTING
12.15.26 STC04347 DSNL004I -xxxx DDF START COMPLETE
605 LOCATION xxxxxxxx
605 LU xxxxxxxx.xxxxxxxx
605 GENERICLU -NONE
605 DOMAIN xxx.xxx.xxx.xxx
605 TCPPORT nnnn
605 SECPORT nnnnn
605 RESPORT nnnn
605 IPNAME -NONE
605 OPTIONS:
605 PKGREL = COMMITHere VTAM/SNA usage is not disallowed as IPNAME is -NONE. You can also issue the -DIS DDF command on your stand-alone Db2 subsystem or on all members of your Db2 data-sharing group and verify that the output looks like:
DSNL080I xxxxx DSNLTDDF DISPLAY DDF REPORT FOLLOWS:
DSNL081I STATUS=STARTD
DSNL082I LOCATION LUNAME GENERICLU
DSNL083I xxxxxxxx xxxxxxxx.xxxxxxxx -NONE
DSNL084I TCPPORT=nnnn SECPORT=nnnnn RESPORT=nnnn IPNAME=-NONE
DSNL085I IPADDR=::xxx.xxx.xxx.xxxDSNL084I value IPNAME=-NONE is what you must look for and hopefully *not* find!
Now, in another subsystem, I have IPNAME set so the BSDS print looks like:
LOCATION=xxxxxxxx IPNAME=yyyyyyy PORT=nnnn SPORT=nnnnn RPORT=nnnn
ALIAS=(NULL)
IPV4=xxx.xxx.xxx.xxx IPV6=NULL
GRPIPV4=xxx.xxx.xxx.xxx GRPIPV6=NULL
LUNAME=xxxxxxxx PASSWORD=(NULL) GENERICLU=(NULL)and when DDF starts it reports:
12.15.36 STC04358 DSNL003I -xxxx DDF IS STARTING
12.15.37 STC04358 DSNL004I -xxxx DDF START COMPLETE
713 LOCATION xxxxxxxx
713 LU -NONE
713 GENERICLU -NONE
713 DOMAIN -NONE
713 TCPPORT nnnn
713 SECPORT nnnnn
713 RESPORT nnnn
713 IPNAME yyyyyyy
713 OPTIONS:
713 PKGREL = COMMIT
713 WLB = DFLTThe IPNAME is set to something and the LU is not set, even though it *is* set in the BSDS – much better!
Again, you can also issue the -DIS DDF command on your stand-alone Db2 subsystem or on all members of your Db2 data-sharing group and verify that the output looks like:
DSNL080I xxxxx DSNLTDDF DISPLAY DDF REPORT FOLLOWS:
DSNL081I STATUS=STARTD
DSNL082I LOCATION LUNAME GENERICLU WLB
DSNL083I xxxxxxxx -NONE -NONE DFLT
DSNL084I TCPPORT=nnnn SECPORT=nnnnn RESPORT=nnnn IPNAME=yyyyyyy
DSNL085I IPADDR=::xxx.xxx.xxx.xxxNow in the DSNL084I the value IPNAME=yyyyyyy is what you must look for and hopefully find!
Delete Delete Delete
The last piece of the VTAM/SNA puzzle, is to clean up your CDB afterwards just to make sure no old and unused, and now completely unusable, definitions are lying around. They annoy auditors and so I would recommend deleting all of the VTAM/SNA definitions that you might still have. Our DORA give-away last year (SecurityAudit HealthCheck) listed all these out for you to do exactly that. It is well worth downloading and running as it is free! Putting it simply, just review, and then delete, all the rows in the tables SYSIBM. LULIST, LUMODES, LUNAMES and MODESELECT.
Hooray!
With these two freebies you can easily check if your systems are:
- Db2 Vnext ready
- DORA and PCI DSS V4.0.1 Compliant!
Pretty cool for nothing huh?
TTFN
Roy Boxwell