This month, I am going to tell you a true story from our labs in Düsseldorf, where I learnt a few things about Db2 and how the Db2 Directory works…
What is it?
The Db2 Directory is the “shadow” catalog if you like. It is basically the machine-readable stuff that echoes what is in some of the Db2 Catalog tables that we all know and love and use nearly every day!
Whatya got?
Well, the Db2 Directory is the DSNDB01 database and, up until Db2 10, was completely hidden from view when looking at it with SQL. The VSAM datasets were there but you could not select from them – Pretty useless! My company, Software Engineering GmbH, actually wrote an assembler program to read the SYSLGRNX table and output the interesting data therein so that it could be used for image copy decisions etc. But, then IBM finally decided to open up the Db2 Directory to our prying eyes! (Sad footnote: They still output the LGRDBID and LGRPSID as CHAR(2) fields!!! Completely useless for joining of course – See my older blogs all about SYSLGRNX and doing the conversion to a correct SMALLINT way of doing it!
Tables, Tables, Tables
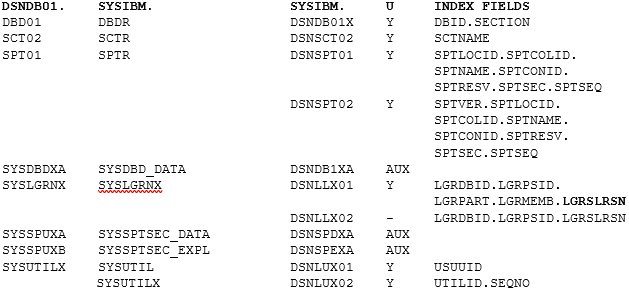
You actually do not have that much data available for use with it!
U is Unique index Y or – for Duplicates allowed and AUX for the standard LOB AUX Index. Bold field names are DESC order.
This table gives you an overview of what you get and also shows the two tablespaces that were, for me at least, of special interest!
Where’s the Beef?
On my test system, the tablespaces SYSSPUXA and SYSSPUXB were both getting larger and larger. Now the task is to understand why you need to know which of the above tables is “linked” to which other ones, and then which link to the Db2 Catalog tables. Time for another table!
So?
What you can see from this, is that the DSNDB01.SPT01 (which we know is the SYSIBM.SPTR) is linked to a whole bunch of Package-related tables and this is all documented – so far, so good! What got me interested, were the LOB tablespaces SYSSPUXA and SYSSPUXB. In my system they were taking up 13,929 and 6,357 Tracks respectively. Might not sound much to a real shop out there, but for me with only 118,000 rows in the SPTR it piqued my interest!
What is in it?
The SYSSPUXA (Table SYSSPTSEC_DATA) contains the machine-readable access paths generated by BIND/REBIND with versioning etc. so that being quite big was, sort of, OK. The SYSSPUXB (Table SYSSPTSEC_EXPL) contains *only* the EXPLAIN-related information for the access path. This was added a few Db2 releases ago so that you could extract the current access path without doing a REBIND EXPLAIN(YES) as that would show the access path “right now” as opposed to what it was, and still is, from, say, five years ago. These two access paths might well be completely different!
How many?
The SPTR had 6,630 tracks.
The SYSSPTSEC_DATA had 13,929 tracks.
The SYSSPTSEC_EXPL had 6,357 tracks.
This is a total of 1,795 Cylinders for 118,553 rows of data – for me, that’s a huge amount.
What is “in” there?
I quickly saw that there were *lots* of versions of packages and some very odd “ghosts” lurking in the data. Here’s a little query to give you a glimpse:
SELECT SUBSTR(SP.SPTCOLID, 1, 18) AS COLLID
, SUBSTR(SP.SPTNAME, 1, 8) AS NAME
, SUBSTR(SP.SPTVER, 1 , 26) AS VERSION
, HEX(SP.SPTRESV) AS RESERVED
FROM SYSIBM.SPTR SP
WHERE 1 = 1
-- AND NOT SP.SPTRESV = X'0000'
AND NOT SP.SPTCOLID LIKE 'DSN%'
AND NOT SP.SPTCOLID LIKE 'SYS%'
LIMIT 100
;
Now, the weird thing is, that the SPTRESV (“RESERVED”) column obviously actually contains the Plan Management number. So, you have “normally” up to three entries. Zero for Original, One for Previous and Two for Current. What I saw, was a large number of Fours!
Set to Stun!
Where did they all come from? A quick bit of looking around revealed that it was Package Phase-In! They have to keep the old and the new executables somewhere… So then, I started trying to work out how to get rid of any old rubbish I had lying around.
FREE This!
First up was a simple FREE generator for old versions of programs deliberating excluding a few of our own packages that require versions for cross-system communications.
WITH NEWEST_PACKAGES (COLLID
,NAME
,CONTOKEN ) AS
(SELECT SP.SPTCOLID
,SP.SPTNAME
,MAX(SP.SPTCONID)
FROM SYSIBM.SPTR SP
WHERE NOT SP.SPTCOLID LIKE 'DSN%'
AND NOT SP.SPTCOLID LIKE 'SYS%'
AND NOT SP.SPTNAME IN ('IQADBACP' , 'IQAXPLN')
GROUP BY SP.SPTCOLID
,SP.SPTNAME
)
SELECT DISTINCT 'FREE PACKAGE(' CONCAT SQ.SPTCOLID
CONCAT '.' CONCAT SQ.SPTNAME
CONCAT '.(' CONCAT SQ.SPTVER
CONCAT '))'
FROM NEWEST_PACKAGES NP
,SYSIBM.SPTR SQ
,SYSIBM.SYSPACKAGE PK
WHERE NP.COLLID = SQ.SPTCOLID
AND NP.NAME = SQ.SPTNAME
AND NP.CONTOKEN > SQ.SPTCONID
AND SQ.SPTCOLID = PK.COLLID
AND SQ.SPTNAME = PK.NAME
AND PK.CONTOKEN > SQ.SPTCONID
AND PK.LASTUSED < CURRENT DATE - 180 DAYS
--LIMIT 100
;
Note that this excludes all IBM packages and my two “SEGUS suspects” and pulls out all duplicates that have also not been executed for 180 days. Running it and then executing the generated FREEs got rid of a fair few, but those “Four” entries were all still there!
FREE What?
Then I found a nice new, well for me anyways, use of the FREE PACKAGE command. You have to be brave, you have to trust the documentation and you trust me because I have run it multiple times now! The syntax must be:
FREE PACKAGE(*.*.(*)) PLANMGMTSCOPE(PHASEOUT)
Do *not* forget that last part!!! Or make sure your resume is up to date!
This then gets rid of all the junk lying around! Was I finished? Of course not… Once it had all been deleted I then had to run a REORG of all these table spaces and so now we come to part two of the BLOG…
REORGing the Directory
Firstly, if you are in Db2 13 you must Reorg the SPT01 and SYSLGRNX anyway to get the new DSSIZE 256GB activated. Secondly, Db2 is clever, so for certain table spaces, it will actually check the LOG to make sure you have taken a COPY:
“Before you run REORG on a catalog or directory table space, you must take an image copy. For the DSNDB06.SYSTSCPY catalog table space and the DSNDB01.DBD01 and DSNDB01.SYSDBDXA directory table spaces, REORG scans logs to verify that an image copy is available. If the scan of the logs does not find an image copy, Db2 requests archive logs.”
Db2 for z/OS Utility Guide and Reference „Before running REORG TABLESPACE“
Pretty clear there!
We are good to go as we only have the SPT01 and its LOBs. Here is an example Utility Syntax for doing the deed:
Pretty simple as the AUX YES takes care of the LOBs. Remember to COPY all objects afterwards as well!
COPY TABLESPACE DSNDB01.SPT01
COPYDDN (SYSC1001)
FULL YES
SHRLEVEL REFERENCE
COPY TABLESPACE DSNDB01.SYSSPUXA
COPYDDN (SYSC1001)
FULL YES
SHRLEVEL REFERENCE
COPY TABLESPACE DSNDB01.SYSSPUXB
COPYDDN (SYSC1001)
FULL YES
SHRLEVEL REFERENCE
How many after?
Once these were all done, I looked back at the track usage:
The SPTR had 4,485 tracks (was 6,630)
The SYSSPTSEC_DATA had 7,575 tracks (was 13,929)
The SYSSPTSEC_EXPL had 4,635 tracks (was 6,357)
This is a total of 1,113 Cylinders (was 1,795) for 90,858 (was 118,553) rows of data.
This is very nice saving of 25% which was worth it for me!
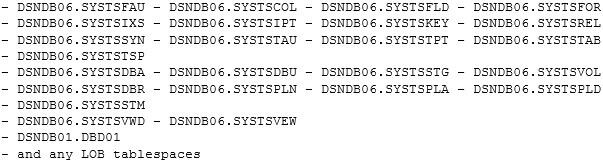
Directory Tips & Tricks
Finally, a mix-n-match of all things Directory and Catalog.
Remember to always reorg the Directory and the Catalog table spaces in tandem.
Remember to always do a COPY before you do any reorgs!
FASTSWITCH YES is ignored for both Catalog and Directory reorgs.
Any more Limits?
Yep, you cannot REORG the DSNDB01.SYSUTILX at all. Only hope here is IDCAMS Delete and Define – dangerous!
LOG YES is required if SHRLEVEL NONE is specified for the catalog LOB table spaces.
If SHRLEVEL REFERENCE is specified, LOG NO must be specified.
The SORTDEVT and SORTNUM options are ignored for the following catalog and directory table spaces:
The COPYDDN and RECOVERYDDN options are valid for the preceding catalog and directory tables if SHRLEVEL REFERENCE is also specified.
Inline statistics with REORG TABLESPACE are not allowed on the following table spaces:
IBM now pack a complete Catalog and Directory REORG with the product to make it nice and easy to schedule and run! Look at member <your.db2.hlq>.SDSNSAMP(DSNTIJCV) for details.
To REORG or not to REORG?
This is the eternal question! For Db2 13 you must do at least two table space REORGs, as previously mentioned, but the hard and fast rule about the complete Db2 Catalog and Directory is: about once per year is normally sufficient. If you notice BIND/PREPARE times starting to go horribly wrong then a REORG is probably worth it, and it may be time to check the amount of COLGROUP statistics you have!
The recommendation from IBM is, “before a Catalog Migration or once every couple of years, and do more REORG INDEX than REORG TS.”
I am now keeping an eagle eye on my Db2 Directory LOBs!
If you have any Directory/Catalog Hints & Tips I would love to hear from you.
This month, I want to go through some of the absolutely most important ZPARMs that control how your Db2 systems behave in a very significant manner. All of the following ZPARMs have a performance impact of some sort. We are always trying to squeeze the last drop of performance out of our Db2 sub-systems, aren’t we?
Db2 13 and Some Db2 12 Updates Ahead!
Since this Newsletter topic first came out, in March 2022, out of the ten ZPARMs listed *five* have got new defaults! I have highlighted all these changed defaults. I have also added three new „Usual Suspects“ to the list of ZPARMs that must be checked…
Starting with the Easy Stuff…
CACHEDYN. YES/NO, default YES. Should always be set to YES – unless you do not care about saving dynamic SQL performance. Back a few decades ago, the recommendation was to have this set to NO as default! Hard to believe that these days, where most shops have 80% – 90% dynamic SQL during the day!
Now we Get to the Numerics!
OUTBUFF. 400 – 400,000, default 102,400. This is *extremely* important and you really should set it to the highest possible value you can afford in real memory! As a minimum, it should be 102,400 KB (100MB). This is the buffer that Db2 uses to write log records before they are „really“ written to disk. The larger the buffer, the greater the chance that, in case of a ROLLBACK, the data required is in the buffer and not on disk.
Skeletons in the Closet?
EDM_SKELETON_POOL. 5,120 – 4,194,304, default 81,920. This is one of my personal favorites, (I wrote a newsletter solely on this a few years ago). I personally recommend at least 150,000 KB and actually even more if you can back it with real memory. Just like OUTBUFF, pour your memory in here but keep an eye on paging! If Db2 starts to page, you are in serious trouble! Raising this can really help with keeping your DSC in control.
DBDs are Getting Bigger…
EDMDBDC. 5,000 – 4,194,304, default 40,960. The DBD Cache is getting more and more important as, due to UTS usage, the size of DBDs is increasing all the time.
DSC is Always Too Small!
EDMSTMTC. 5,000 – 4,194,304, default 113,386. The EDM Statement Cache (really the Dynamic Statement Cache) is where Db2 keeps a copy of the prepared statements that have been executed. So when the exact same SQL statement with the exact same set of flags and qualifiers is executed, Db2 can avoid the full prepare and just re-execute the statement. This is basically a no-brainer and should be set to at least 122,880 KB. Even up to 2TB is perfectly OK. Remember: A read from here is *much* faster than a full prepare, so you get a very quick ROI and great value for the memory invested! Keep raising the value until your flushing rates for DSC drop down to just 100’s per hour, if you can! Remember to cross check with the EDM_SKELETON_POOL ZPARM as well. It always takes two to Tango…
How Many SQLs?
MAXKEEPD. 0 – 204,800, default 5,000. The Max Kept Dyn Stmts parameter is how many prepared SQLs to keep past commit or rollback. It should be set to a minimum of 8,000 or so. Raising this might well cause a large memory demand in the ssidDBM1 address space so care must be taken.
RIDs Keep Getting Longer…
MAXRBLK. 0, 128 – 2,000,000, default 1,000,000. RID POOL SIZE is the maximum amount of memory to be available for RID Block entries. It should be at least 1,000,000 and, if you can, push it to the maximum of 2,000,000. Unless you want to switch off all RID Block access plans, in which case you set it to zero – Obviously not really recommended!
Sorts Always Need More Space
MAXSORT_IN_MEMORY. 1000 to SRTPOOL. Default 2000. The maximum in-memory sort size is the largest available space to complete ORDER BY, GROUP BY or both SQL Clauses. Remember that this is per thread, so you must have enough memory for lots of these in parallel. The number should be between 1,000 and 2,000, but whatever value you choose, it must be less than or equal to the SRTPOOL size.
Sparse or Pair-wise Access?
MXDTCACH. 0 – 512, default 20. Max data caching is the maximum size of the sparse index or pair-wise join data cache in megabytes. If you do not use sparse index, pair-wise join, or you are not a data warehouse shop, then you can leave this at its default. Otherwise, set it to be 41 MB or higher. If it is a data warehouse subsystem, then you could set this as high as 512 MB. (This ZPARM replaced the short-lived SJMXPOOL, by the way.)
Sort Node Expansion
SRTPOOL. 240 – 128,000, default 20,000. SORT POOL SIZE is the available memory that is needed for the sort pool. IFCID 96 can really help you size this parameter. Remember that the number of sort nodes leapt up from 32,000 in Db2 11 to 512,000 nodes for non-parallelism sorts and 128,000 nodes for a sort within a parallel child task in Db2 12. This means raising this ZPARM can have an even greater positive effect than before.
The Three New Guys on the Block!
To the MAX!
DSMAX used to be around 20,000 and can now be between 1 – 400,000. Remember that you will never actually reach this maximum limit as it is 31-bit memory-constrained.
Thrashing Around…
NPGTHRSH. Valid values are 0 or 1 – 2147483647. Default up to Db2 11 was 0, from Db2 12 default is now 1. SAP systems use a default of 10. The big change here, was in Db2 12 when the change from „no statistics ever ran“ of -1 forced the value to be the „optimizer default“ of 501 instead of the real value -1. This is also why the default is now 1 ,so that this ZPARM has a normal use! Setting it to 0 means that the access path chosen will always only be cost based.
Lock ‚em Up and Throw Away the Key!
NUMLKUS. 0 – 104857600, with a default of 20,000. Just be careful raising this value too high, as each lock will take 540 bytes of storage in the IRLM!
Your „Top Ten List“ + Three
These thirteen ZPARMs really influence how your Db2 system works and so must always be checked and changed with great care and attention to detail. Always do a before and after appraisal to see whether or not changing them helped or hindered your system!
If you have any comments, or other ZPARMs you think are also important for performance, feel free to drop me a line!
IDUG 2023 NA
IDUG is nearly upon again. I will be there in Philadelphia at the SEGUS booth and doing a fair bit of moderating as well. Drop on by, have a chat and pick up some of our swag and join me at the „Roy reviews AI with our WorkloadExpert“ PSP on Thursday for a chance to win some cool stuff.
OK, I kept you all waiting long enough… Here are my AI results with Db2 13 FL501!
Start at the Start
We begin with the beginning as last time:
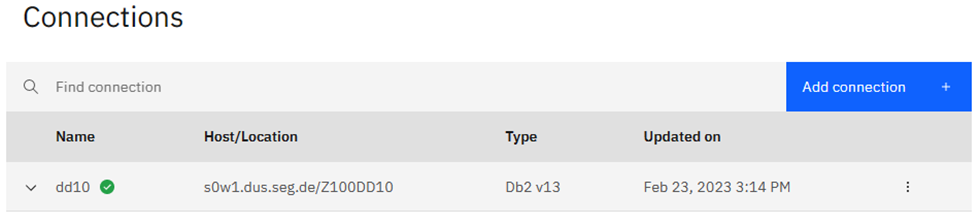
Let’s get Connected!
Here you can see that I have already defined my little test Db2 13 system to the system:
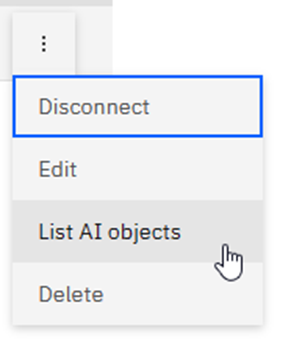
Join the Dots …
Now just click on the vertical dots:
Here you can Disconnect, Edit (Which shows you the same window as “add connection”), List AI objects or Delete.
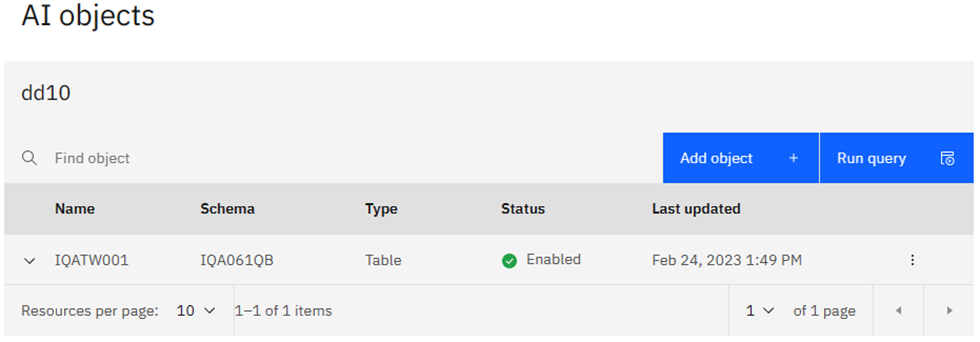
What do we have?
Choosing List AI objects you see what has been created:
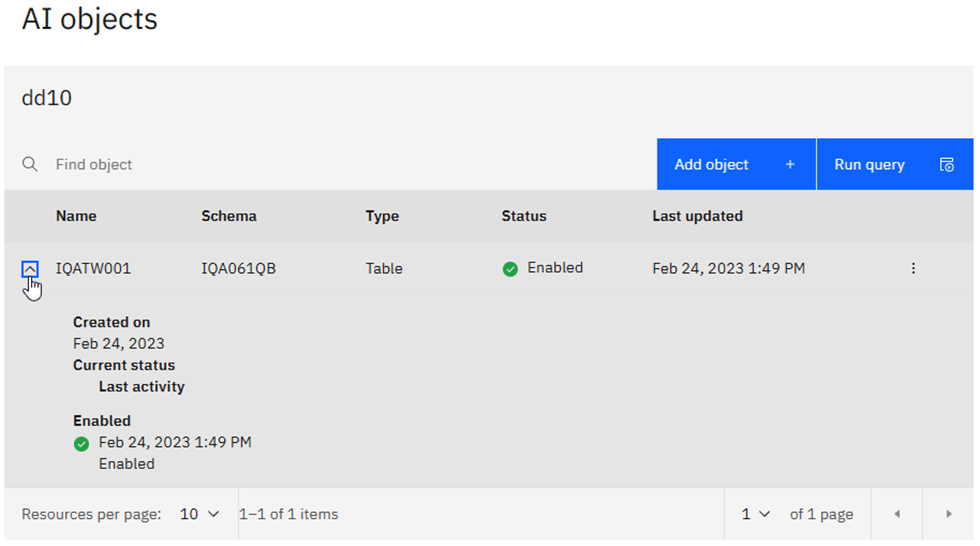
Clicking on the down arrow on the left-hand side to expand looks a lot better than last month:
Clickedy-click-click
Now, clicking on the vertical dots on the right hand side, you can choose to Disable AI query or Enable AI query. (I have actually added a new column for consideration, so first I clicked on Disable and then clicked again on Enable)
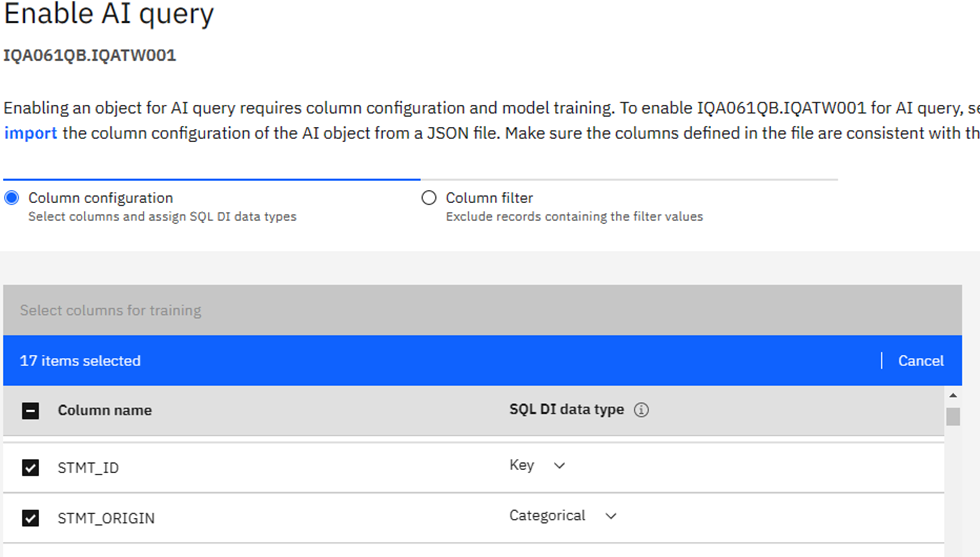
Just the Facts, Ma’am – Again
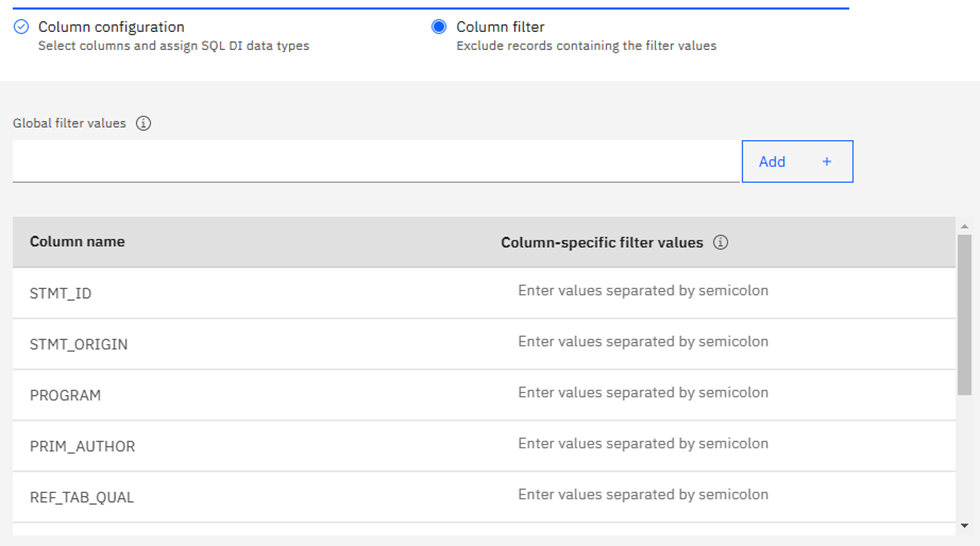
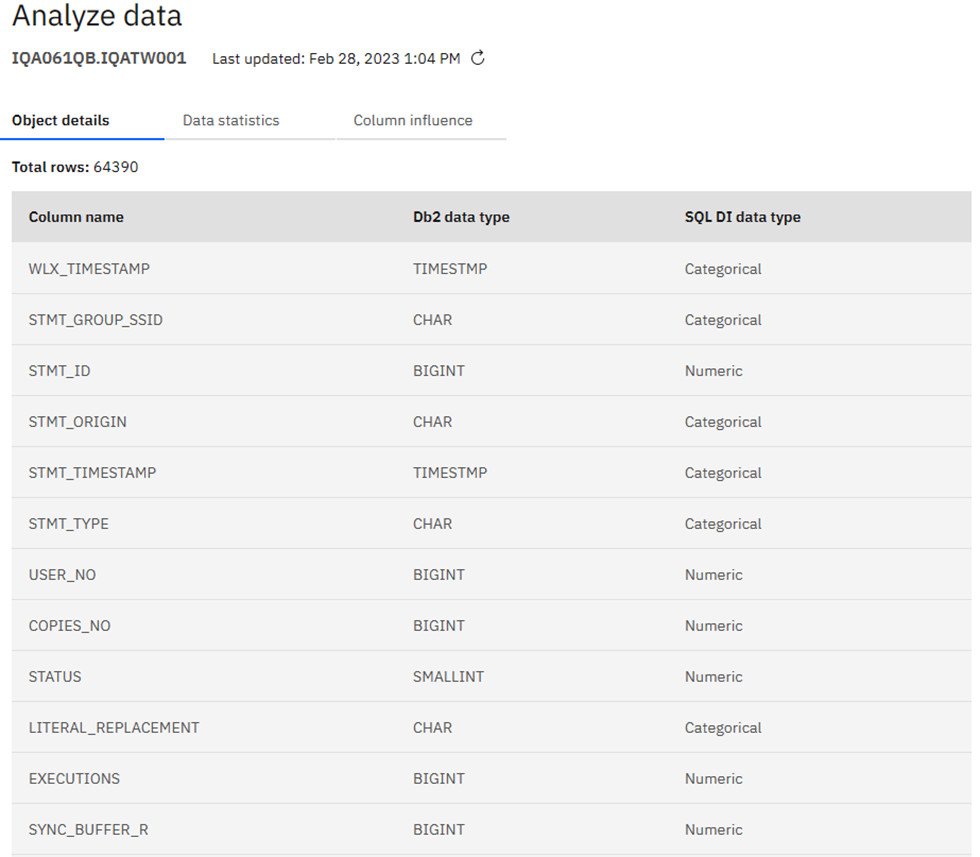
Here you must make your “Usual Suspects” decision: which columns to actually use in building the AI Model. I am using our WorkLoadExpert performance table in this newsletter and have selected 17 columns that I think will work together nicely. Only one can be a “Key” column – I choose STMT_ID in this case. Once you are done selecting columns, click on the big blue “Next” button where you may then add additional filters to remove any rows you know are to be ignored:
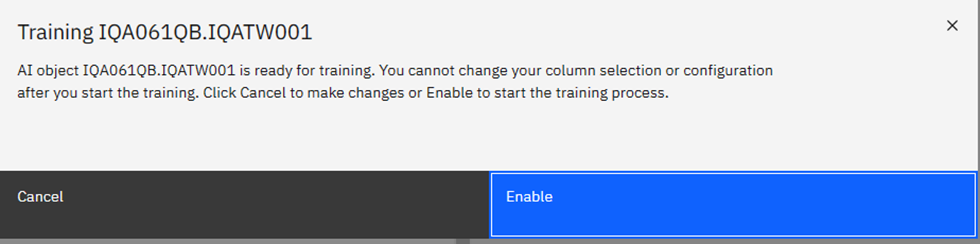
Playing Chicken?
When done, click on the big blue “Enable” button and you get your last chance to chicken out:
SIO and CPU Records!
Click here and then get a cup of coffee….or go to SDSF and marvel at how much CPU and IO Spark actually uses and does this as the light bulbs dim in your part of the world…
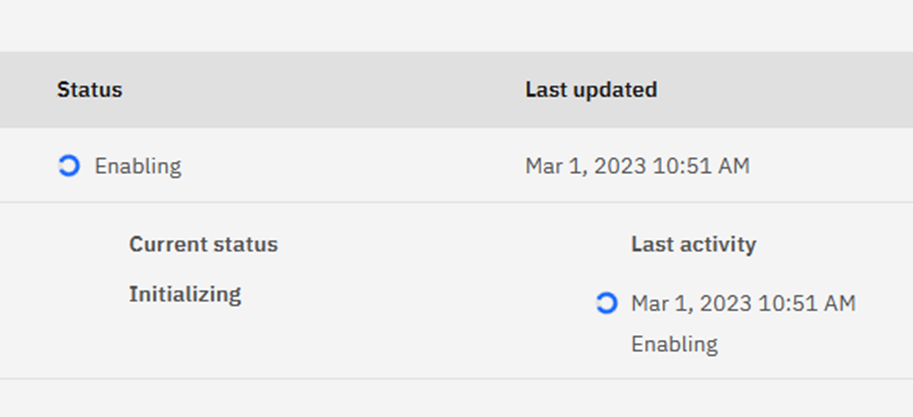
You Keep me Spinning
Oddly, at least when I do this, the Initializing spinning wheels:
Right Round and Around
… never stop. The WLM Stored procedure for utilities was finally kicked off about 40 minutes later:
J E S 2 J O B L O G -- S Y S T E M
10.43.19 STC09611 ---- WEDNESDAY, 01 MAR 2023 ----
10.43.19 STC09611 $HASP373 DD10WLMU STARTED
10.43.19 STC09611 IEF403I DD10WLMU - STARTED - TIME=10.43.19
10.43.19 STC09611 ICH70001I SQLDIID LAST ACCESS AT 09:37:37
A Loaded Question?
And loaded all the required data:
ICE134I 0 NUMBER OF BYTES SORTED: 99083595
ICE253I 0 RECORDS SORTED - PROCESSED: 49173, EXPECTED: 49173
A quick exit and re-logon to the web interface…and Tra la!
Not only AI but Dr Who!
It is also strange that it seems to be in a time machine, one hour in advance of my local…Anyways, my new data is there and so onward! (I have since heard that our time zone setting is actually to blame and that just going back one level, and then forward again, stops the spinning wheel problem. However, just wait until Spark finishes and the stored procedure has loaded your data!)
Never Trust a Statistic You haven’t Faked Yourself!
Clicking on Data statistics shows:
Influencer of the Day?
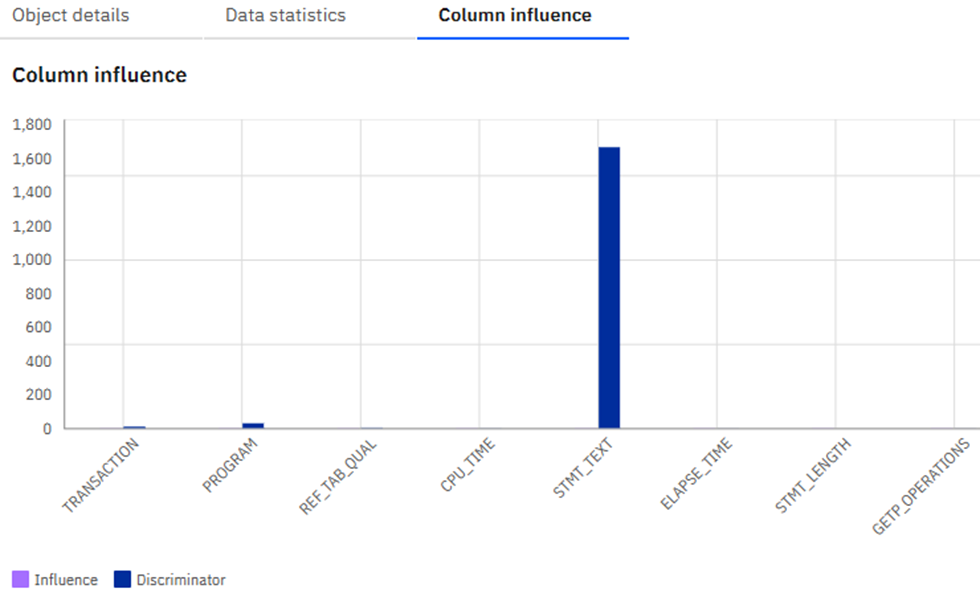
Then you can look at the Column influence:
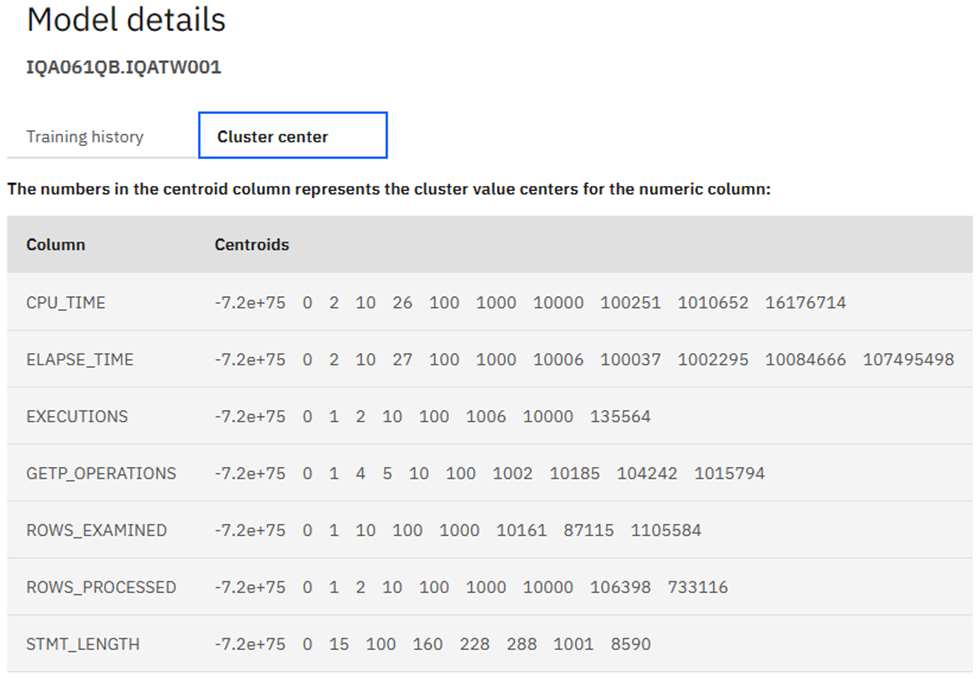
Super Model?
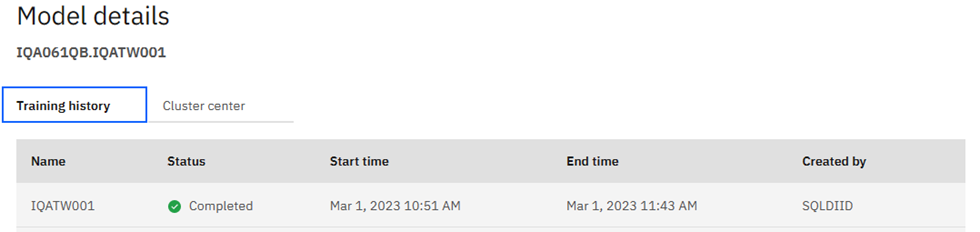
Back at the top you can then review the Model details:
Or just a Cluster….
Here are the Cluster center details:
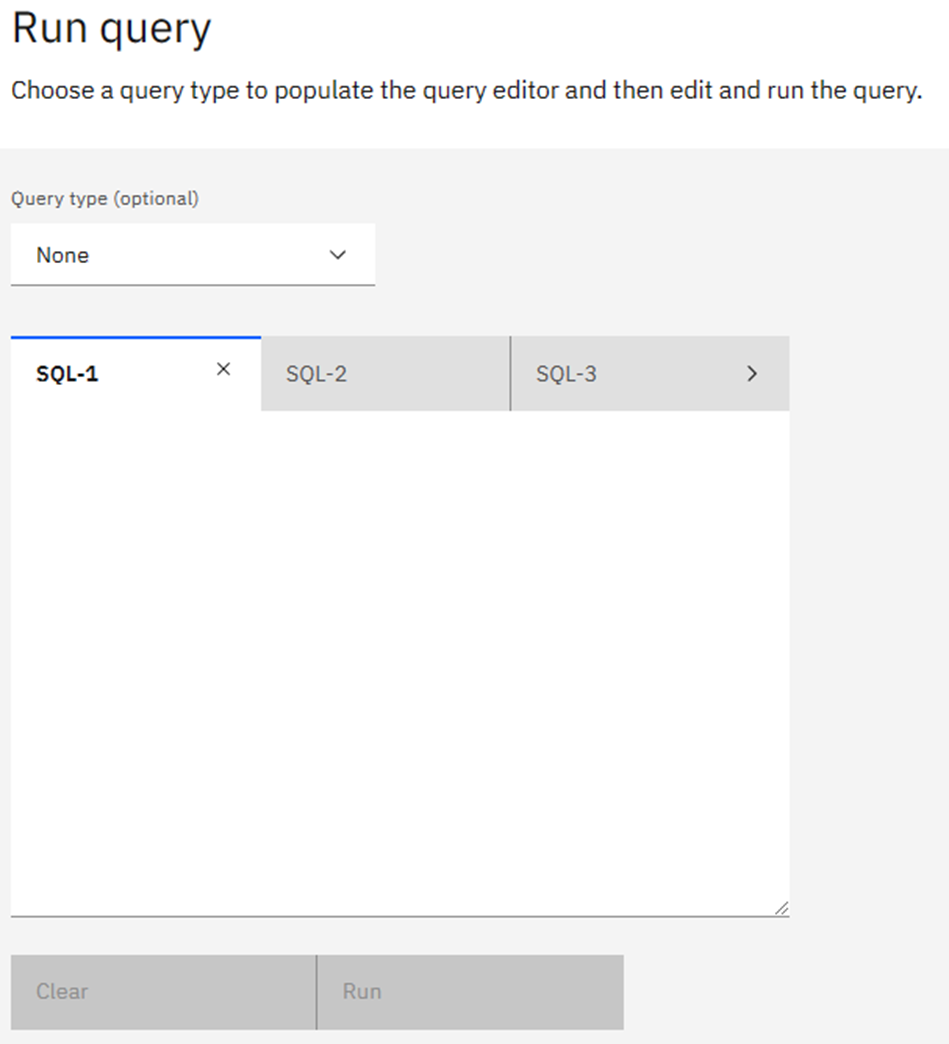
Going back to the List AI Objects window, there are two blue buttons: Add object and Run query. I did not discuss Run Query last month but it gives you a SPUFI-like ability on the PC, tailored to the AI BiFs:
Lets RUN Away!
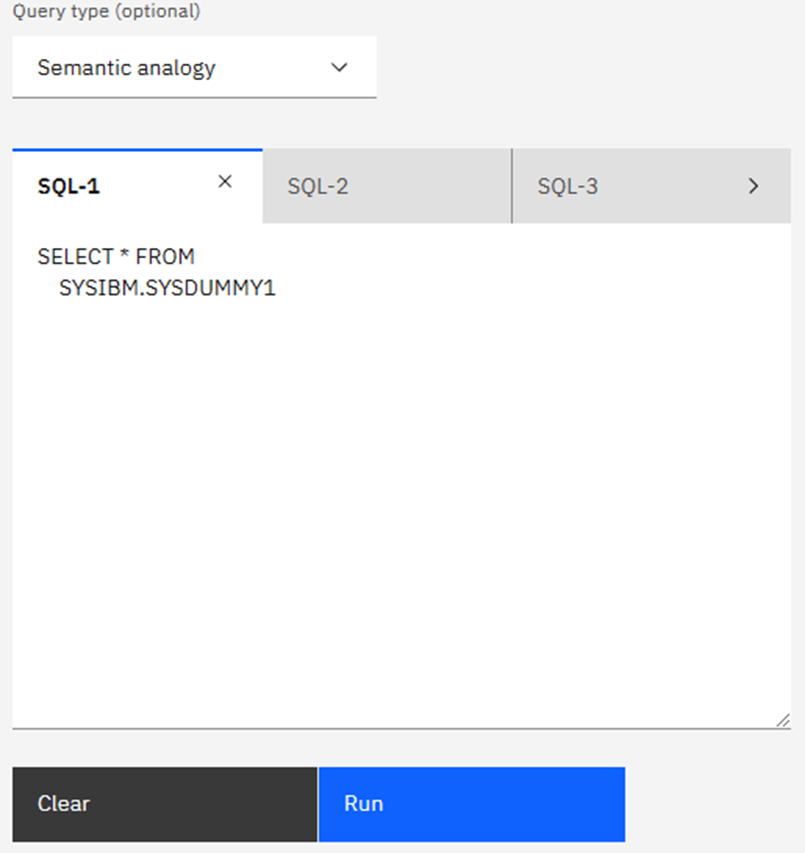
Clicking on Query type gives a drop-down list of the basic AI BiFs where it then gives you an example SQL (based on the documentation, *not* on any AI Tables you might have done!). Once you type in any query the “run” box turns blue:
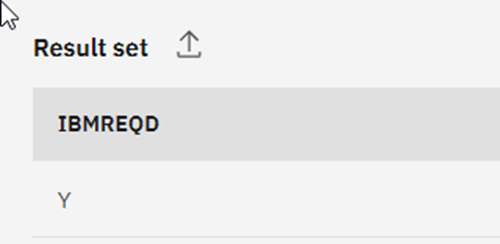
It Works!
Click run and see the results:
Data Review
Once the model is trained, you can then review on the host what it has done. In SPUFI you can find details of what you have done in the pseudo Db2 catalog tables that support Data Insights, (I have removed a ton of rows to make this readable – sort of!):
SELECT * FROM
SYSAIDB.SYSAIOBJECTS ;
---------+---------+---------+---------+---------+---------+---------+---------+-------+-
OBJECT_ID OBJECT_NAME OBJECT_TYPE SCHEMA NAME
---------+---------+---------+---------+---------+---------+---------+---------+-------+-
26 -------------------------------- T IQA061QB IQATW001
-------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+
STATUS CONFIGURATION_ID MODEL_ID CREATED_BY CREATED_DATE
-------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+
Enabled 36 36 SQLDIID 2023-02-24-07.57.42.086932
-------+---------+---------+---------+---------+---------+---------+---------+
LAST_UPDATED_BY LAST_UPDATED_DATE DESCRIPTION
-------+---------+---------+---------+---------+---------+---------+---------+
SQLDIID 2023-03-01-10.43.38.407460 ----------------
SELECT * FROM
SYSAIDB.SYSAICONFIGURATIONS ;
---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+-----
CONFIGURATION_ID NAME OBJECT_ID RETRAIN_INTERVAL KEEP_ROWIDENTIFIER_KEY
---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+-----
36 -------------------------------- 26 ---------------- Y
---+---------+-------
NEGLECT_VALUES
---+---------+-------
---+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+--------
CREATED_BY CREATED_DATE LAST_UPDATED_BY LAST_UPDATED_DATE
---+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+--------
SQLDIID 2023-03-01-09.51.00.994421 SQLDIID 2023-03-01-09.51.00.994461
SELECT * FROM
SYSAIDB.SYSAICOLUMNCONFIG
ORDER BY 1 , 3 , 2 ;
--+---------+---------+---------+---------+---------+---------+---------+---------+---------+
CONFIGURATION_ID COLUMN_NAME COLUMN_AISQL_TYPE COLUMN_PRIORITY NEGLECT_VALUES
--+---------+---------+---------+---------+---------+---------+---------+---------+---------+
36 END_USERID C H
36 PRIM_AUTHOR C H
36 PROGRAM C H
36 REF_TABLE C H
36 REF_TAB_QUAL C H
36 STMT_ORIGIN C H
36 STMT_TEXT C H
36 TRANSACTION C H
36 WORKSTATION C H
36 COPIES_NO I H
.
.
.
36 WLX_TYPE I H
36 WORKSTATION_OLD I H
36 STMT_ID K H
36 CPU_TIME N H
36 ELAPSE_TIME N H
36 EXECUTIONS N H
36 GETP_OPERATIONS N H
36 ROWS_EXAMINED N H
36 ROWS_PROCESSED N H
36 STMT_LENGTH N H
When the column COLUMN_AISQL_TYPE has a value of “I” it means it is ignored by AI processing. Also note that this table SYSAICOLUMNCONFIG gets two extra columns (COLUMN_VECTOR_CARDINALITY and MAX_DATA_VALUE_LEN) once you apply the vector prefetch upgrade APARs:
For IBM Z AI Optimization (zAIO) library and IBM Z AI Embedded (zADE) library in the IBM Z Deep Neural Network (zDNN) stack on z/OS: • Apply OA63950 and OA63952 for z/OS 2.5 (HZAI250). • Apply OA63949 and OA63951 for z/OS 2.4 (HBB77C0).
For OpenBLAS on z/OS: • Apply PH49807 and PH50872 for both z/OS 2.5 and z/OS 2.4 (HTV77C0). • Apply PH50881 for z/OS 2.5 (HLE77D0). • Apply PH50880 for z/OS 2.4 (HLE77C0).
For Db2 13 for z/OS, apply PH51892. Follow the instructions for DDL migration outlined in the ++ HOLD text. By default, the new Db2 subsystem parameter MXAIDTCACH is set to 0, indicating that vector prefetch is disabled. To enable vector prefetch, set MXAIDTCACH to a value between 1 and 512. This parameter is online changeable. See “IBM Db2 13 for z/OS documentation” on MXAIDTCACH.
For SQL Data Insights 1.1.0 UI and model training (HDBDD18), apply PH51052.
Further, the table SYSAIMODELS got a new column MODEL_CODE_LEVEL and an increase in size for the METRIC column to 500K with the above APARs.
SELECT * FROM
SYSAIDB.SYSAIMODELS ;
---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------
MODEL_ID NAME OBJECT_ID CONFIGURATION_ID VECTOR_TABLE_CREATOR
---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------
36 -------------------------------- 26 36 DSNAIDB
+---------+---------+--
VECTOR_TABLE_NAME
+---------+---------+--
AIDB_IQA061QB_IQATW001
+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+
VECTOR_TABLE_STATUS VECTOR_TABLE_DBID VECTOR_TABLE_OBID VECTOR_TABLE_IXDBID VECTOR_TABLE_IXOBID VECTOR_TABLE_VERSION
+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+
A 329 3 329 4 1
-------+---------+---------+---------+---------+---------+---------+---------+-------
METRICS
-------+---------+---------+---------+---------+---------+---------+---------+-------
[{"discriminator":8.59443984950101,"influence":0.9367419701380996,"name":"TRANSACTION",
-------+---------+---------+
INTERPRETABILITY_STRUCT
-------+---------+---------+
-------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+----
CREATED_BY CREATED_DATE LAST_UPDATED_BY LAST_UPDATED_DATE
-------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+----
SQLDIID 2023-03-01-09.51.03.777504 SQLDIID 2023-03-01-10.43.37.796847
---+---------+---------+---------+---------+--
MODEL_ROWID
---+---------+---------+---------+---------+--
2495E518C773B081E09C018000000100000000002213
SELECT * FROM
SYSAIDB.SYSAICOLUMNCENTERS
ORDER BY 1 , 2 , 3 ;
----+---------+---------+---------+---------+---------+---------+
MODEL_ID COLUMN_NAME CLUSTER_MIN LABEL
----+---------+---------+---------+---------+---------+---------+
36 CPU_TIME -0.7200000000000000E+76 EMPTY
36 CPU_TIME +0.0 E+00 c0
36 CPU_TIME +0.2000000000000000E+01 c1
36 CPU_TIME +0.1617671400000000E+08 c9
36 ELAPSE_TIME -0.7200000000000000E+76 EMPTY
36 ELAPSE_TIME +0.0 E+00 c0
36 ELAPSE_TIME +0.2000000000000000E+01 c1
36 ELAPSE_TIME +0.1008466600000000E+08 c9
36 ELAPSE_TIME +0.1074954980000000E+09 c10
SELECT * FROM
SYSAIDB.SYSAITRAININGJOBS ;
---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+--------+-------
TRAINING_JOB_ID OBJECT_ID CONFIGURATION_ID MODEL_ID STATUS PROGRESS RESOURCE
---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+--------+-------
33 26 33 33 F 0
34 26 34 34 F 0
35 26 35 35 C 100
36 26 36 36 C 100
-+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+------
MESSAGES
-+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+------
{"messages":"failed to train model: Something went wrong with the zLoad, please check the SQL DI log for more details.","resumeI
{"messages":"failed to train model: Something went wrong with the zLoad, please check the SQL DI log for more details.","resumeI
{"messages":"model training is completed","sparkSubmitId":"driver-20230224105851-0002"}
{"messages":"model training is completed","sparkSubmitId":"driver-20230301085133-0003"}
-+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+----
START_TIME END_TIME CREATED_BY CREATED_DATE
-+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+----
2023-02-24-08.01.20.737455 2023-02-24-08.51.56.386011 SQLDIID 2023-02-24-08.01.20.737455
2023-02-24-10.52.27.687965 2023-02-24-11.43.22.095144 SQLDIID 2023-02-24-10.52.27.687965
2023-02-24-11.58.20.109571 2023-02-24-12.49.20.660143 SQLDIID 2023-02-24-11.58.20.109571
2023-03-01-09.51.03.777662 2023-03-01-10.43.38.407414 SQLDIID 2023-03-01-09.51.03.777662
---+---------+---------+---------+---------+---------+------
LAST_UPDATED_BY LAST_UPDATED_DATE
---+---------+---------+---------+---------+---------+------
SQLDIID 2023-02-24-08.51.56.386030
SQLDIID 2023-02-24-11.43.22.095164
SQLDIID 2023-02-24-12.49.20.660160
SQLDIID 2023-03-01-10.43.38.407425
KPIs from my Data
Here are a few KPIs from these first test runs:
SELECT COUNT(*) FROM IQA061QB.IQATW001 ;
64390
SELECT COUNT(*) FROM DSNAIDB.AIDB_IQA061QB_IQATW001 ;
49173
SELECT SUBSTR(A.COLUMN_NAME, 1, 12) AS COLUMN_NAME
, SUBSTR(A.VALUE , 1, 12) AS VALUE
, A.VECTOR
FROM DSNAIDB.AIDB_IQA061QB_IQATW001 A
ORDER BY 1 , 2 ;
---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+--
COLUMN_NAME VALUE VECTOR
---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+--
CPU_TIME c0 3E594822BC9D2C7A3CD4F61DBD37E5033D34B314BD4CF8E3BD4B4D47BCB6CE293D1DBA1A3D858FDF3DC4DF08BD9E77753CCED43F
CPU_TIME c1 3D9214383CFE4C90BDB3DFE4BBE407563BBA69553DB48FEFBCF39451BC6BABF0BDA31BDFBDB52F883C30B992BC8D71AF3D9E54FF
ELAPSE_TIME c0 3E55B744BCCC5CED3D129B14BC9E553C3C9B121EBD8949C0BD4F838DBD1582A33D36D6363DA1F72F3DBCB033BDAFB88F3D4DE348
ELAPSE_TIME c1 3DE390AC3D2DCC98BD2DF437BC5B7F713D766D103BD1AC10BB48E2C43B9FA9E6BD80D5D7BDC40AFE3CE586C9BCACADE93DFE2745
END_USERID BOXWEL2 3D505075BD80E40F3D3AAB60BBA463F6BBCC51C43D92B118BD044D20BD8C6B3B3CC315133BBB087A3DC1D5923DC4EB763D039C8B
END_USERID BOXWEL3 3D2FB919BC5013E3BD6652DDBD4654DA3DA4AC83BA70024FBD7FAFD0BCF16670BB2CCB4B3DBE32E93DFE13383CB052283C82FD46
As I mentioned last month the vector tables are very “special”!
What now?
So now we have analyzed a bunch of SQL WorkLoadExpert data from our own labs. What can we do?
First up, I wish to see what user KKKKKKK does with dynamic SQL that is “similar” to what I do with table IQATW001 but I am only interested in those SQLs where the AI thinks it is more than 0.5 (so very analogous):
SELECT AI_ANALOGY('BOXWEL3' USING MODEL COLUMN PRIM_AUTHOR,
'IQATW001' USING MODEL COLUMN REF_TABLE ,
'KKKKKKK' USING MODEL COLUMN PRIM_AUTHOR,
REF_TABLE ) AS AI_VALUE
,A.WLX_TIMESTAMP
,A.STMT_ID
,A.STMT_TIMESTAMP
,SUBSTR(A.PRIM_AUTHOR , 1 , 8 ) AS PRIM_AUTHOR
,SUBSTR(A.PROGRAM , 1 , 8 ) AS PROGRAM
,SUBSTR(A.REF_TABLE , 1 , 18) AS REF_TABLE
,A.EXECUTIONS
,A.GETP_OPERATIONS
,A.ELAPSE_TIME
,A.CPU_TIME
,A.STMT_TEXT
FROM IQA061QB.IQATW001 A
WHERE A.PRIM_AUTHOR = 'KKKKKKK'
AND AI_ANALOGY('BOXWEL3' USING MODEL COLUMN PRIM_AUTHOR,
'IQATW001' USING MODEL COLUMN REF_TABLE ,
'KKKKKKK' USING MODEL COLUMN PRIM_AUTHOR,
REF_TABLE )
> 0.5
ORDER BY 1 DESC -- SHOW BEST FIRST
--ORDER BY 1 -- SHOW WORST FIRST
FETCH FIRST 2000 ROWS ONLY ;
All interesting stuff! I use dynamic SQL to INSERT into the table a lot, and it has determined that use of dynamic SQL with tables R510T002 and IQATA001 is analogous. In fact, it is! The SQLs were all INSERT, DELETE and UPDATE… Clever ol’ AI!
Dynamic Duo?
Now I wish to see which programs process dynamic SQL like the IBM DSNTIAD and DSNTIAP programs:
SELECT AI_SEMANTIC_CLUSTER( PROGRAM,
'DSNTIAD',
'DSNTIAP') AS AI_VALUE
,A.WLX_TIMESTAMP
,A.STMT_ID
,A.STMT_TIMESTAMP
,SUBSTR(A.PROGRAM , 1 , 8) AS PROGRAM
,A.EXECUTIONS
,A.GETP_OPERATIONS
,A.ELAPSE_TIME
,A.CPU_TIME
,A.STMT_TEXT
FROM IQA061QB.IQATW001 A
WHERE A.PROGRAM NOT IN ('DSNTIAD', 'DSNTIAP')
AND A.STMT_ORIGIN = 'D'
ORDER BY 1 DESC -- SHOW BEST FIRST
--ORDER BY 1 -- SHOW WORST FIRST
FETCH FIRST 10 ROWS ONLY ;
Again, very nice – it spotted all of the RealTime DBAExpert Dynamic SQL access programs in use…
Undynamic Duo?
Ok, now the opposite of that query, show me the SQLs that are like them but not them!
SELECT AI_SEMANTIC_CLUSTER( PROGRAM,
'DSNTIAD',
'IQADBACP',
'SEDBTIAA') AS AI_VALUE
,A.WLX_TIMESTAMP
,A.STMT_ID
,A.STMT_TIMESTAMP
,SUBSTR(A.PRIM_AUTHOR , 1 , 8) AS PRIM_AUTHOR
,SUBSTR(A.PROGRAM , 1 , 8) AS PROGRAM
,SUBSTR(A.REF_TABLE , 1 , 18) AS REF_TABLE
,A.EXECUTIONS
,A.GETP_OPERATIONS
,A.ELAPSE_TIME
,A.CPU_TIME
,A.STMT_TEXT
FROM IQA061QB.IQATW001 A
WHERE A.PROGRAM NOT IN ('DSNTIAD', 'IQADBACP' ,'SEDBTIAA')
--AND A.STMT_ORIGIN = 'D'
--ORDER BY 1 DESC -- SHOW BEST FIRST
ORDER BY 1 -- SHOW WORST FIRST
FETCH FIRST 10 ROWS ONLY ;
Aha! It found a little assembler program that fires off SQL like the top three!
The Apple doesn’t Fall far from the Tree
Finally, I want to see which programs behave like IQADBACP (our main dynamic SQL driver program):
SELECT AI_SIMILARITY( PROGRAM,
'IQADBACP') AS AI_VALUE
,A.WLX_TIMESTAMP
,A.STMT_ID
,A.STMT_TIMESTAMP
,SUBSTR(A.PROGRAM , 1 , 8) AS PROGRAM
,A.EXECUTIONS
,A.GETP_OPERATIONS
,A.ELAPSE_TIME
,A.CPU_TIME
,A.STMT_TEXT
FROM IQA061QB.IQATW001 A
WHERE NOT A.PROGRAM = 'IQADBACP'
AND A.STMT_ORIGIN = 'D'
ORDER BY 1 DESC -- SHOW BEST FIRST
--ORDER BY 1 -- SHOW WORST FIRST
FETCH FIRST 10 ROWS ONLY;
And the output:
---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---
AI_VALUE WLX_TIMESTAMP STMT_ID STMT_TIMESTAMP PROGRAM
---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---
+0.4575602412223816E+00 2023-02-02-10.45.26.535375 7 2023-01-17-16.50.54.118774 O2DB6X
+0.4575602412223816E+00 2023-01-06-05.27.28.779825 7 2023-01-17-16.50.54.118774 O2DB6X
+0.4400676488876343E+00 2023-01-06-05.27.28.779825 220 2023-01-20-10.11.14.618038 DSMDSLC
+0.4400676488876343E+00 2023-01-06-05.27.28.779825 222 2023-01-20-10.11.38.136712 DSMDSLC
+0.4400676488876343E+00 2023-01-06-05.27.28.779825 221 2023-01-20-10.11.21.993833 DSMDSLC
+0.4400676488876343E+00 2023-01-06-05.27.28.779825 252 2023-01-20-10.55.07.078652 DSMDSLC
+0.4400676488876343E+00 2023-01-06-05.27.28.779825 251 2023-01-20-10.54.37.901247 DSMDSLC
+0.4400676488876343E+00 2023-01-06-05.27.28.779825 233 2023-01-20-10.47.23.961076 DSMDSLC
+0.4400676488876343E+00 2023-01-06-05.27.28.779825 232 2023-01-20-10.46.59.756430 DSMDSLC
+0.4400676488876343E+00 2023-01-06-05.27.28.779825 224 2023-01-20-10.33.42.609175 DSMDSLC
+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+-
EXECUTIONS GETP_OPERATIONS ELAPSE_TIME CPU_TIME STMT_TEXT
+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+---------+-
0 0 0 0 SELECT COALESCE(COALESCE(A.DBNAME,B.DBNAME),C
2 7 27753 1236 SELECT COALESCE(COALESCE(A.DBNAME,B.DBNAME),C
2 1387 57974 14900 SELECT CASE WHEN B.VCATNAME < ' ' THEN '00000
6 4170 68943 53330 SELECT CASE WHEN B.VCATNAME < ' ' THEN '00000
6 4596 286233 99773 SELECT CASE WHEN B.VCATNAME < ' ' THEN '00000
1 851 55367 42542 SELECT CASE WHEN B.VCATNAME < ' ' THEN '00000
1 298 122961 24848 SELECT CASE WHEN B.VCATNAME < ' ' THEN '00000
2 1260 68272 48952 SELECT CASE WHEN B.VCATNAME < ' ' THEN '00000
1 192 3395 2508 SELECT CASE WHEN B.VCATNAME < ' ' THEN '00000
3 810 43520 23771 SELECT CASE WHEN B.VCATNAME < ' ' THEN '00000
Again, it found all of the correct programs.
Quibble Time!
I did find some small problems…
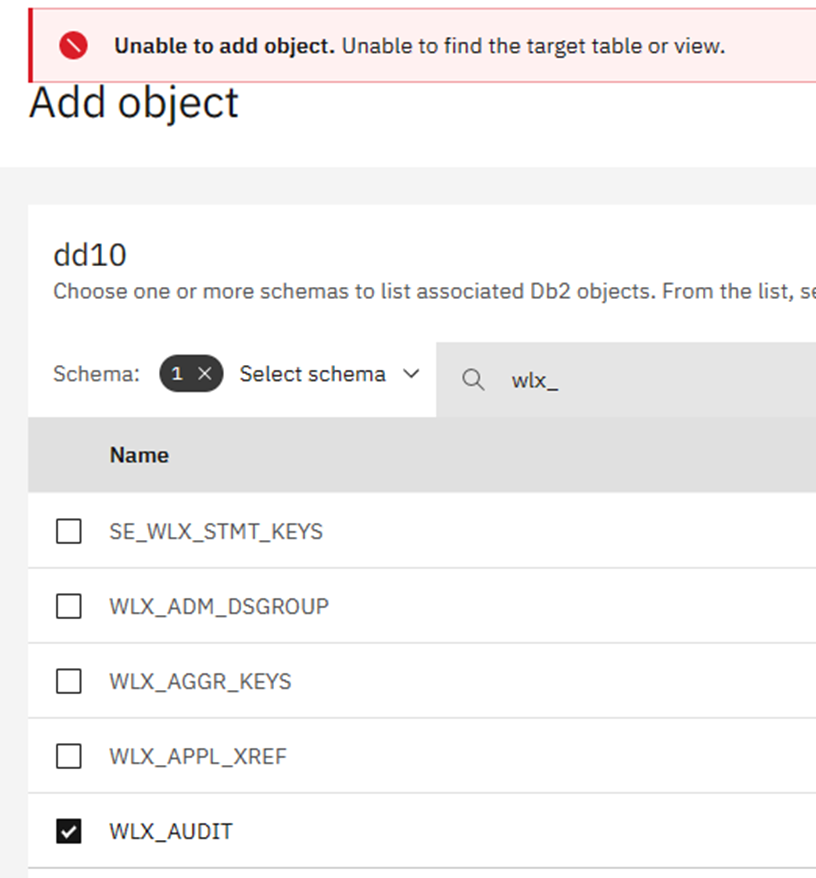
I use ALIASes a lot and they appear in the drop-down selection box when in “Add object”, but if you choose one as an AI Object:
This then leads on to the second quibble… The red windowed error messages stay there until you click them away… This can lead you to believe that a problem exists when in reality everything is groovy!
I also found out that the spinning wheel completes if you wait for Spark and LOAD and then go back and forward on the panel.
Finally, the way you move around the product is a bit odd… sometimes you use the browser back function, sometimes you click on a “Back” button, sometimes you click on a bread crumb, sometimes there are multiple options hidden under triple vertical dots which change depending on where you are in the process.
I am sure these little UI bugs will all get ironed out very quickly!
End of Quibbles.
First Baby Steps Taken!
This little trip into the AI world is really just the tip of the iceberg. I will be doing many more AI queries over the coming months, and I hope to show all my results, either here or in another one of my Newsletters and/or at the German GUIDE in April 2023 and, hopefully, at the IDUG 2023 as well.
Any questions about AI, do not fear to ask, and when not me then ChatGPT!
TTFN
Roy Boxwell
Um unsere Webseite für Sie optimal zu gestalten und fortlaufend verbessern zu können, verwenden wir Cookies. Lehnen Sie Cookies ab, stehen einige Funktionen der Website nicht zur Verfügung. Weitere Informationen hierzu erhalten Sie in unserer Datenschutzerklärung.